1. 起因
我们的Java项目使用了SpringBoot 2.7.x + gradle 7.6.1。
最初的打包方式,比较简单直接:
gradle clean
gradle service:build
通过两句命令即可获得最终打包的jar包。
随着项目的发展,打包速度变得越来越慢。尤其在加入单测、自定义gradle任务等等一些用来做特定校验的task之后,流水线的周期变得更长了,后期我们可能还会引入checkstyle\findBugs等功能,势必会导致流水线进一步变慢。
很影响CI CD的效率。
为此,我们做了一些尝试。
2. 性能优化之路
不同阶段做的优化措施,根据时间线排布,大概如下所示:
2.1 引入Docker Image的Multi Stage Build
参考文档: https://docs.docker.com/build/building/multi-stage/
原本Docker Image编译的过程,大概是这样的:
基于一个基础镜像,基础镜像内包含编译+运行所需的依赖
执行编译命令:gradle clean && gradle build,下载依赖、编译jar包
得到jar包,挪到特定的位置
配置一下镜像的entrypoint
Dockerfile大概这样:
From base
...
CP ./code ./
RUN gradle clean
RUN gradle build
CP ./build/libs/app.jar ./jar
ENTRY_POINT...这种做法的缺点是:
编译依赖和运行依赖是两套东西,都放到最终镜像里,导致镜像体积臃肿
如果不手动清理,镜像里可能还会有很多编译jar包的中间产出
每次编译,都需要重新下载一次所有的jar包,速度非常慢
总结就是镜像打包很慢,镜像体积很大,进而导致镜像推送、拉拉取、服务的更新,一整个流程上的所有环节都变慢。
Docker的多阶段编译是Docker推出的一种解决方案,思路就是,把编译和运行环境做分离。
前置的阶段,负责编译结果,最终的镜像负责拿到前面的编译结果,准备运行环境。
这样的好处是:
可以更好的利用Docker的Build Cache,Docker镜像是分层的,把灵活变化的层和相对稳定的层区分开来,更有助于docker进行缓存优化,从而加快整体的编译速度
最终镜像仅仅包括了最小的运行时依赖,体积最优,内容最干净。
优化后,大概是这样的:
FROM build-image:latest AS BUILD
COPY . .
RUN gradle clean
RUN gradle build
FROM runtime-image:latest
COPY --from=Build ./build/libs/app.jar ./app.jar
...经过这一步,我们优化了:
最终镜像体积
部分缓解了编译的速度。
但是,紧接着,聚焦的点在于:gradle 编译非常慢。
2.2 引入存放依赖的镜像层
gradle编译时,加上-i标志位,就可以打印出运行细节。
耗时的大头就是依赖下载,可以占到1-2分钟。
这里不难理解,每次docker build,把代码拷贝到镜像里的时候,都是全新的环境,没有任何本地缓存,这个时候,就是全量的依赖下载,这个量级是很恐怖的。
我们常用的依赖,版本大多是固定的,除了少数自己维护的类库版本,一直处于snapshot阶段,每次都需要强制下载最新的版本。
其他依赖相对固定,大可不必每次都下载,针对这种情况,我们引入了一个新的镜像:gradle缓存镜像。
这个镜像的作用就是每天凌晨时,下载代码库所需要的依赖库,然后存放到特定位置。
实际编译的时候,编译镜像从这个依赖镜像里拷贝依赖库即可。
由于大部分依赖库变动不大,一天更新一次足矣维持有效性。
存放依赖的镜像Dockerfile大致长这样:
ARG GRADLE_CACHE_HOME=/home/.gradle
FROM base-image AS Build
RUN gradle clean
RUN gradle jar --refresh-dependencies --no-build-cache --no-configuration-cache -i -x test -g $GRADLE_CACHE_HOME
FROM alpine:3.14
ARG GRADLE_CACHE_HOME
COPY --from=Build $GRADLE_CACHE_HOME $GRADLE_CACHE_HOME
打包jar包的镜像改造之后:
FROM build-image:latest AS BUILD
COPY --from=gradle-cache:latest /home/.gradle /home/.gradle
COPY . .
RUN gradle clean
RUN gradle build
FROM runtime-image:latest
COPY --from=Build ./build/libs/app.jar ./app.jar
...经过这次改造,编译时间再次缩短到一分半左右,相对来说是比较好接受的了。
但是随着代码的演变,新的问题出现了。
2.3 针对gradle自定义task的优化
我们的Java微服务采用DDD的编码风格进行开发。
开发时,有一个规定:Domain层的包不能依赖其他层,也就是不能引入其他层的依赖。
所以我们自定义了一个gradle task进行校验,在上线打包镜像时,执行这个task,确保在最后一步进行拦截不合规的代码。
这个时候发现,原本一分半就能执行完的编译任务,现在需要三分多钟,把编译日志拉出来,这个自定义task执行了一分半左右,占了整体docker build的一半左右。
这个task的定义大概长这样:
tasks.register('check', JavaCompile) {
group 'verification'
sourceSets {
main {
java {
srcDirs = ['src/main/java']
// 设置编译的范围
......
}
}
}
dependsOn tasks.classes
}原理就是仅编译domain层的代码,确保不引入其他依赖的前提下能编译通过。
编译全部代码才40s左右,编译部分代码,为什么会需要90s呢?
查了下,目前常见论坛里,几乎没有对这种情况的描述与建议。
经过一番研究,我看到了gradle的官方文档里关于自定义task的优化建议:
https://docs.gradle.org/7.6.1/userguide/performance.html#enable_incremental_build_for_custom_tasks
除了一些常见的内容,其中一个建议让人眼前一亮:
Incremental Build。
task的模型可以这么理解:
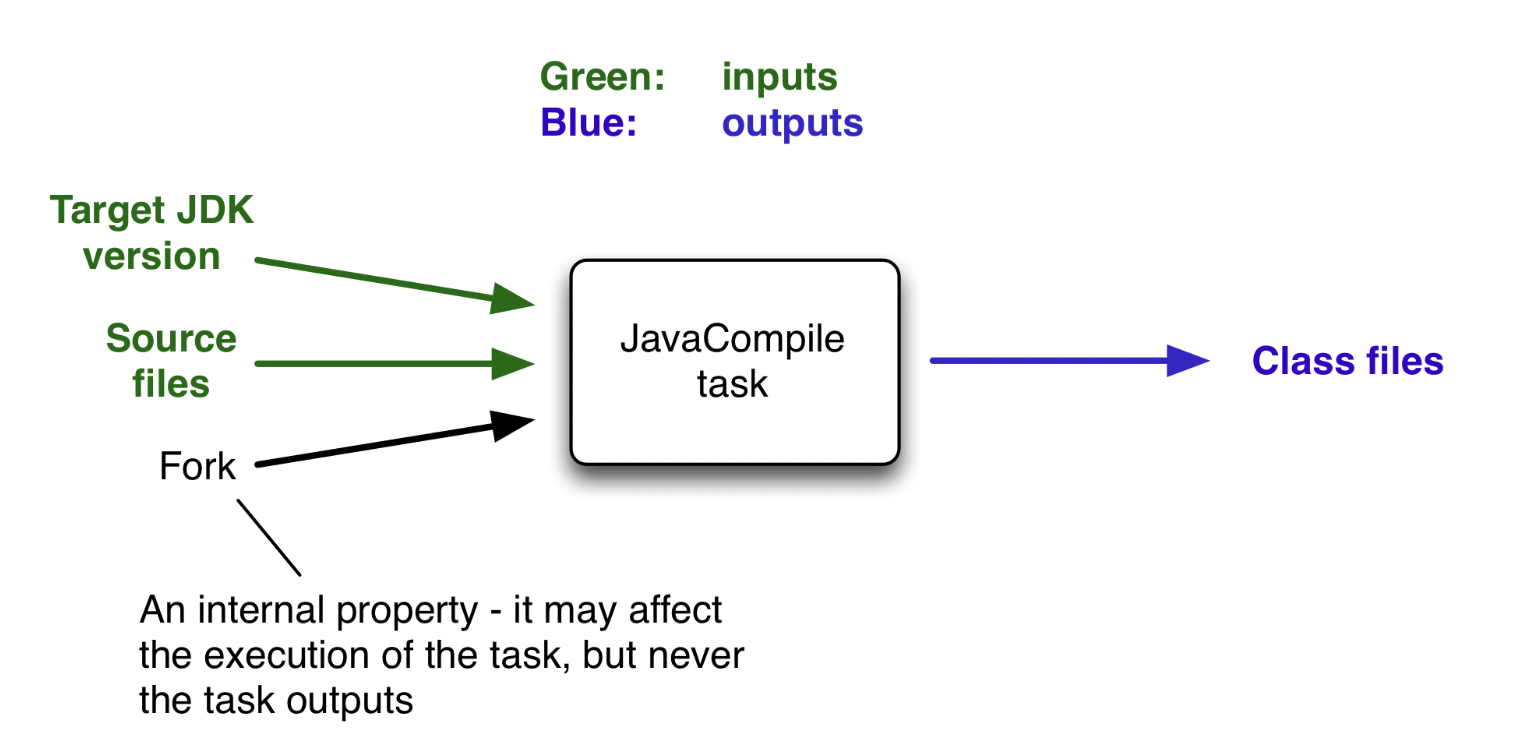
每个task都有自己的输入和输出,也就是inputs和outputs,gradle针对任务的优化,也就是基于inputs和outputs,如果监测到这个task本次执行时:
inputs和上次执行相比没有变化,那么gradle可以从缓存中读取上次编译的outputs,而无需再次执行。
inputs相比上次有新增,那么可以只针对新增的部分,进行处理,然后和上次的outputs merge
inputs相比上次有减少,那么只针对减少的部分,进行处理,然后和上次的outputs merge
这个机制叫做增量编译 incremental build。
所以在编译的日志里,我们经常可以看到,gradle的任务执行,后面会跟着这几种标签描述:
- EXECUTED:Task executed its actions.
- UP-TO-DATE:Task’s outputs did not change.
- FROM-CACHE:Task’s outputs could be found from a previous execution.
- SKIPPED:Task did not execute its actions.
- NO-SOURCE:Task did not need to execute its actions.
对应的就是增量编译的不同情况。
文档里解释:官方自带的所有task,例如build,都默认使用了这样的逻辑进行优化,但是自定义的task,需要开发手动进行兼容,来启用这一特性。
关键字:指定inputs和outputs、显式开启增量编译。
改造后的task定义:
tasks.register('check', JavaCompile) {
group 'verification'
// 使用增量编译 API
inputs.files sourceSets.main.java.matching {
// 设置编译的范围
......
}
outputs.dir("....")
options.incremental = true
sourceSets {
main {
java {
srcDirs = ['src/main/java']
// 设置编译的范围
......
}
}
}
dependsOn tasks.classes
}经过这样的优化,自定义任务的耗时从90s,下降到16s。
看起来已经很好了,那么,还有其他措施吗?
有的。
2.4 启用Gradle Build Cache Node 远程编译缓存
Gradle的一大优势就是他的缓存管理手段。
但是Docker编译时,gradle的缓存管理其实是部分失效了,因为每次都是全新的编译环境,每次产生的编译信息,无法得到复用。
我在本地尝试,开启缓存和不开启缓存,编译的速度差距可以有10-20秒。
由此可见,影响还是比较大的。
这就需要更进一步,看下gradle的缓存机制怎么运作了。
首先缓存有:
- Build cache
- Configuration cache
分别存放编译产出缓存和任务配置信息,比如运行依赖关系。
根据缓存的不同位置,gradle提供: - local缓存
- remote缓存
我们可以通过在setting.gradle里添加如下设置来开启缓存:
buildCache {
local {
directory = "${rootProject.projectDir}/.gradle/build-cache"
}
remote(HttpBuildCache) {
url = 'http://xxxx/cache/'
allowInsecureProtocol = true
allowUntrustedServer = true
}
}本地编译缓存通过会默认开启。
远程缓存却很少使用,但是它的优势,很明显:
适用于docker build的场景,在前后两次build之间提供缓存,而且无需占用本地机器的空间
开发者首次编译时,可以获取远端的缓存信息来加快编译
那么该怎么构建build cache node呢?可以参考文档:
https://docs.gradle.com/build-cache-node/
简而言之,gradle提供了三种方式:
起jar包进程
开箱即用的docker镜像,本地起一个缓存服务
部署到k8s上,暴露给更大范围的用户
其实说白了,都是一样的原理,无非就是jar包跑在不同的环境里,这里我直接在k8s里起一个服务,通过ingress暴露出来。
经过这样的优化,编译速度再一次加快了16s左右。
build cache node还提供了简单的ui,可以看到目前的缓存信息:

不过这种方式里,记得要设置访问用户的权限。
2.5 其他
除了上述的一些措施,还有一些小的tips,可以关注。
gradle build的时候,会在后台起一个daemon线程,做一些监测优化,每执行一个task,就会起一次,在本地没有影响,daemon起来后,就一直活跃在后台。
但是在docker build的时候,由于是分层编译,每次起完,执行完task就被退出了,再次执行,就会再起一次。
反复起停daemon线程也会耗费几秒钟的时间,
针对这种情况,比较简单的就是合并task的多条语句,放一起执行:
原来:
RUN gradle clean
RUN gradle build
RUN gradle check其实可以写成
gradle clean build check 此外,我们还有开启—parallel的方式让他们并行执行。
这些也是可以酌情优化的地方。
发表回复
要发表评论,您必须先登录。