Contents
本文篇幅较长,预计需要2-3小时的阅读时间
Programing In K8s :Client-go 实现分析与二次开发
1. 简介
K8s具有标准的C\S结构,API Server 作为唯一与内部存储ETCD进行通信的组件,充当了集群中唯一一个服务端的角色;其他组件,例如kubelet、Kube-Proxy、Kubectl、Kube-Schedule以及各种资源的controller,都可以看作是某种客户端,承担自身职责的同时,需要同API Server保持通信,以实现K8s整体的功能。
Client-go就是所有广义K8s客户端的基础库,一方面,K8s各个组件或多或少都用到它的功能,另一方面,它的代码逻辑和组件自身的逻辑深度解耦,如果想要阅读、学习K8s的源码,client go很适合作为入门组件。
Client-go作为一个活跃的开源项目,应对一些场景时,它采用的解决方案已经被大家在实践中广泛验证过,作为一名运维或者后端开发,熟悉、了解这些解决方案,对自己去解决工作中的一些问题,想必也有很大的助力。
本文涉及的内容、源码分析、撰写的demo,全部依据目前client-go最新的代码版本 V14.0。
github地址: https://github.com/kubernetes/client-go
2. Client-go 结构

RESTClient是所有客户端的父类,底层调用了Go语言net\http库,访问API Server的RESTful接口。
RESTClient的操作相对原始,使用样例如下:
// 构建config对象,通常会存放在~/.kube/config的路径;如果运行在集群中,会有所不同
config, err := clientcmd.BuildConfigFromFlags("", clientcmd.RecommendedHomeFile)
// 封装error判断
mustSuccess(err)
config.APIPath = "api"
config.GroupVersion = &corev1.SchemeGroupVersion
config.NegotiatedSerializer = scheme.Codecs
restClient, err := rest.RESTClientFor(config)
mustSuccess(err)
result := &corev1.PodList{}
// 实际是在Do方法里调用了底层的net/http库向api-server发送request,最后将结果解析出放入result中
err = restClient.Get().Namespace("sandbox").Resource("pods").
VersionedParams(&metav1.ListOptions{Limit: 40}, scheme.ParameterCodec).
Do(context.TODO()).Into(result)
mustSuccess(err)
for _, d := range result.Items {
fmt.Printf("NameSpace: %v \t Name: %v \t Status: %+v \n", d.Namespace, d.Name, d.Status.Phase)
}
ClientSet是使用最多的客户端,它继承自RESTClient,使用K8s的代码生成机制(client-gen机制),在编译过程中,会根据目前K8s内置的资源信息,自动生成他们的客户端代码(前提是需要添加适当的注解),使用者可以通过builder pattern进行初始化,得到自己在意的目标资源类型的客户端。ClientSet如同它的名字一样,代表的是一组内置资源的客户端。
例如:
clientset, err := kubernetes.NewForConfig(config) // 根据config对象创建clientSet对象
mustSuccess(err)
podClient := clientset.CoreV1().Pods("development") // 根据Pod资源的Group、Version、Recource Name创建资源定制客户端,传入的字符串表示资源所在的ns;podClient对象具有List\Update\Delete\Patch\Get等curd接口DynamiClient动态客户端,可以根据传入的GVR(group version resource)生成一个可以操作特定资源的客户端。但是不是内存安全的客户端,返回的结果通常是非结构化的。需要额外经过一次类型转换才能变为目标资源类型的对象,这一步存在内存安全的风险。相比ClientSet,动态客户端不局限于K8s的内置资源,可以用于处理CRD(custome resource define)自定义资源,但是缺点在于安全性不高。DynamicClient使用的样例代码如下:
结构化的类型通常属于k8s runtime object的子类型;非结构化的对象通常是map[string]interface{}的形式,通过一个字典存储对象的属性;K8s所有的内置资源都可以通过代码生成机制,拥有默认的资源转换方法
dynamicClient, err := dynamic.NewForConfig(config)
mustSuccess(err)
gvr := schema.GroupVersionResource{Version: "v1", Resource: "pods"}
// 返回非结构化的对象
unstructObj, err := dynamicClient.Resource(gvr).Namespace("sandbox").List(context.TODO(), metav1.ListOptions{Limit: 40})
mustSuccess(err)
podList := &corev1.PodList{}
// 额外做一次类型转换,如果这里传错类型,就会有类型安全的风险
err = runtime.DefaultUnstructuredConverter.FromUnstructured(unstructObj.UnstructuredContent(), podList)
mustSuccess(err)
for _, po := range podList.Items {
fmt.Printf("NAMESPACE: %v \t NAME: %v \t STATUS: %v \n", po.Namespace, po.Name, po.Status)
}
DiscoveryClient发现客户端,主要用于处理向服务端请求当前集群支持的资源信息,例如命令kubectl api-resources使用的就是发现客户端,由于发现客户端获取的数据量比较大,并且集群的资源信息变更并不频繁,因此发现客户端会在本地建立文件缓存,默认十分钟之内的请求,使用本地缓存,超过十分钟之后则重新请求服务端。DiscoveryClient的使用样例代码如下:
discoveryClient, err := discovery.NewDiscoveryClientForConfig(config)
mustSuccess(err)
_, APIResourceList, err := discoveryClient.ServerGroupsAndResources()
mustSuccess(err)
for _, list := range APIResourceList {
gv, err := schema.ParseGroupVersion(list.GroupVersion)
mustSuccess(err)
for _, resource := range list.APIResources {
fmt.Printf("name: %v \t group: %v \t verison: %v \n",
resource.Name, gv.Group, gv.Version)
}
}
本地缓存路径:
本地存储了serverresources.json文件,感兴趣的可以打开看下,是json格式化后的资源信息。
参考代码文件pkg/kubectl/cmd/apiresources/apiresources.go,可以看到kubectl api-resources命令里确实使用了discoveryClient:
func (o *APIResourceOptions) RunAPIResources(cmd *cobra.Command, f cmdutil.Factory) error {
...
// discoveryCilent
discoveryclient, err := f.ToDiscoveryClient()
if err != nil {
return err
}
// 是否可以读本地缓存
if !o.Cached {
// Always request fresh data from the server
discoveryclient.Invalidate()
}
errs := []error{}
lists, err := discoveryclient.ServerPreferredResources()
...
}总结一下:
| 客户端名称 | 源码目录 | 简单描述 |
|---|---|---|
| RESTClient | client-go/rest/ | 基础客户端,对HTTP Request封装 |
| ClientSet | client-go/kubernetes/ | 在RESTClient基础上封装了对Resource和Version,也就是说我们使用ClientSet的话是必须要知道Resource和Version, 例如AppsV1().Deployments或者CoreV1.Pods,缺点是不能访问CRD自定义资源 |
| DynamicClient | client-go/dynamic/ | 包含一组动态的客户端,可以对任意的K8S API对象执行通用操作,包括CRD自定义资源 |
| DiscoveryClient | client-go/discovery/ | ClientSet必须要知道Resource和Version, 但使用者通常很难记住所有的GVR信息,这个DiscoveryClient是提供一个发现客户端,发现API Server支持的资源组,资源版本和资源信息 |
3. Client-go 内部原理
官方的client-go架构图如下,可以看到Informer机制是里面的核心模块。Informer顾名思义就是消息通知器。是连接本地客户端与API Server的关键。
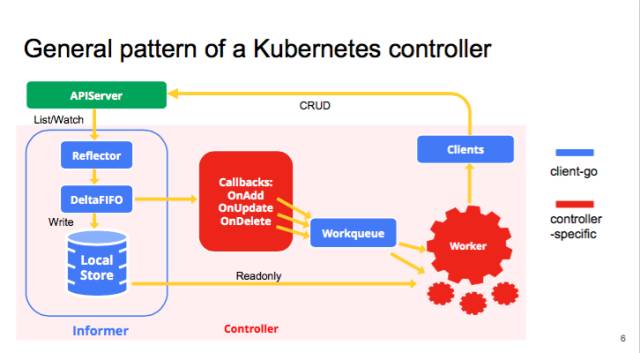
针对Informer中的组件,我们自下而上的分析。
3.1 Indexer
在Informer的结构图中,Local Storage就是Indexer,Indexer字面意思就是索引器,索引器+存储,有经验的开发,大概已经能理解这两者之间的关联了。Indexer通过某种方式构建资源对象的索引,来存储资源对象。相应的,使用者可以依据这种索引,快速检索到自己关注的资源对象。
Indexer是一个继承自Store的接口,Delta_FIFO也同样继承自Store,一个Indexer对象中,可以存在多种不同的索引。
首先看看indexer和Store的声明:
// 文件路径: k8s.io/client-go/tools/cache/index.go
type Indexer interface {
Store // 继承接口Store
// indexName是索引的类型名,obj是一个资源对象,该方法会计算obj在某一个indexer中的索引值,并返回该索引值下已存储的资源对象
Index(indexName string, obj interface{}) ([]interface{}, error)
// indexKey是indexName索引类中一个索引键,函数返回indexKey指定的所有对象键,这个对象键是Indexer内唯一的,在添加的时候会计算
IndexKeys(indexName, indexedValue string) ([]string, error)
// 获取indexName索引类中的所有索引键
ListIndexFuncValues(indexName string) []string
// 和IndexKeys方法类似,只是返回的是对象的list,而不是对象键的list
ByIndex(indexName, indexedValue string) ([]interface{}, error)
// 返回目前所有的indexers
GetIndexers() Indexers
// 添加索引分类
AddIndexers(newIndexers Indexers) error
}
// Store声明 , 文件路径:k8s.io/client-go/tools/cache/store.go
// 接口含义类似一般的KV存储,不做额外解释
type Store interface {
Add(obj interface{}) error
Update(obj interface{}) error
Delete(obj interface{}) error
List() []interface{}
ListKeys() []string
Get(obj interface{}) (item interface{}, exists bool, err error)
GetByKey(key string) (item interface{}, exists bool, err error)
Replace([]interface{}, string) error
Resync() error
}可以看到indexer里面,索引的概念很关键,那么indexer是怎么实现索引的呢?
client-go/tools/cache/index.go内还定义了以下的内容
// 文件路径: k8s.io/client-go/tools/cache/index.go
// 计算索引的函数类型,值得注意的是,这里返回的索引值是一个数组,也就是一个对象可以得到多个索引值
type IndexFunc func(obj interface{}) ([]string, error)
// 计算索引的方法不止一个,通过给他们命名来加以区别,存储索引名与索引方法的映射
type Indexers map[string]IndexFunc
// map a name to a index,和Indexers类似,存储的是索引名与索引的映射
type Indices map[string]Index
// 索引键与值列表的映射
type Index map[string]sets.String 只看说明有一些绕(中文里索引一词,一会儿是动词,一会儿是名词),这里我画了两个图解释一下:
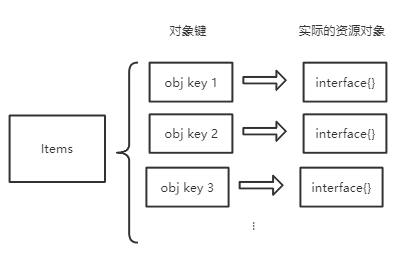
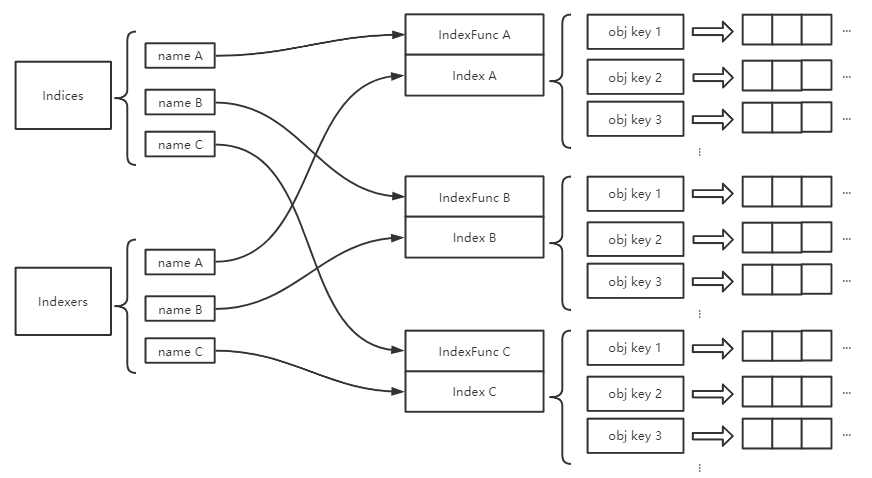
不难发现,其实可以类比MySql里面索引的实现,Items里面存储的是聚簇索引,Index里面存储的是没有数据信息的二级索引,即使在二级索引里找到了对象键,要想找到原始的object,还需要回Items里面查找。
Indexer的结构大致如上所述,但是细心的同学应该发现了,Indexers仅仅是一个接口,不是具体的实现,因为Informer中实际使用的,是类型cache,cache的声明及代码分析如下:
// 文件路径: k8s.io/client-go/tools/cache/store.go
// `*cache` implements Indexer in terms of a ThreadSafeStore and an
// associated KeyFunc.
type cache struct {
// cacheStorage 是一个ThreadSafeStore类型的对象,实际使用的是threadSafeMap类型
cacheStorage ThreadSafeStore
// keyFunc 是用来计算对象键的
keyFunc KeyFunc
}
// 文件路径: k8s.io/client-go/tools/cache/thread_safe_store.go
// threadSafeMap implements ThreadSafeStore
// 这个结构很清晰了,items存储的是对象键与对象的映射,indexers\indices则保存了索引记录、索引方法
type threadSafeMap struct {
lock sync.RWMutex
items map[string]interface{}
// indexers maps a name to an IndexFunc
indexers Indexers
// indices maps a name to an Index
indices Indices
}
// ThreadSafeStore 实现了线程安全的存储接口
type ThreadSafeStore interface {
Add(key string, obj interface{})
Update(key string, obj interface{})
Delete(key string)
Get(key string) (item interface{}, exists bool)
List() []interface{}
ListKeys() []string
Replace(map[string]interface{}, string)
Index(indexName string, obj interface{}) ([]interface{}, error)
IndexKeys(indexName, indexKey string) ([]string, error)
ListIndexFuncValues(name string) []string
ByIndex(indexName, indexKey string) ([]interface{}, error)
GetIndexers() Indexers
// AddIndexers adds more indexers to this store. If you call this after you already have data
// in the store, the results are undefined.
AddIndexers(newIndexers Indexers) error
// Resync is a no-op and is deprecated
Resync() error
}总结一下:
Indexer是Informer实现本地缓存的关键模块。作为Indexer的主要实现,cache是一个存储在内存中的缓存器,初始化时,会指定keyFunc,通常会根据对象的资源名与对象名组合成一个唯一的字符串作为对象键。此外,cache将缓存的维护工作委托给threadSafeMap来完成,threadSafeMap内部实现了一套类似MySql覆盖索引、二级索引的存储机制,用户可以自行添加具有特定索引生成方法的二级索引,方便自己的数据存取。
另外:
K8s内部,目前使用的默认对象键计算方法(也就是cache里面的keyfunc)是MetaNamespaceKeyFunc:
// 文件路径: k8s.io/client-go/tools/cache/store.go
// 不解释,看注释就能懂
// MetaNamespaceKeyFunc is a convenient default KeyFunc which knows how to make
// keys for API objects which implement meta.Interface.
// The key uses the format <namespace>/<name> unless <namespace> is empty, then
// it's just <name>.
func MetaNamespaceKeyFunc(obj interface{}) (string, error) {
if key, ok := obj.(ExplicitKey); ok {
return string(key), nil
}
meta, err := meta.Accessor(obj)
if err != nil {
return "", fmt.Errorf("object has no meta: %v", err)
}
if len(meta.GetNamespace()) > 0 {
return meta.GetNamespace() + "/" + meta.GetName(), nil
}
return meta.GetName(), nil
}k8s内部目前使用的自定义的indexFunc有PodPVCIndexFunc、indexByPodNodeName、MetaNamespaceIndexFunc,选取indexByPodNodeName看一下:
// 文件路径: pkg/controller/daemon/daemon_controller.go
// daemon controller需要监控pod所在的node name,这个需求也非常合理
// 提取active的pod的node name,然后返回
func indexByPodNodeName(obj interface{}) ([]string, error) {
pod, ok := obj.(*v1.Pod)
if !ok {
return []string{}, nil
}
// We are only interested in active pods with nodeName set
if len(pod.Spec.NodeName) == 0 || pod.Status.Phase == v1.PodSucceeded || pod.Status.Phase == v1.PodFailed {
return []string{}, nil
}
return []string{pod.Spec.NodeName}, nil
}3.2 DeltaFIFO
DeltaFIFO其实是两个词:Delta + FIFO,Delta代表变化,FIFO则是先入先出的队列。
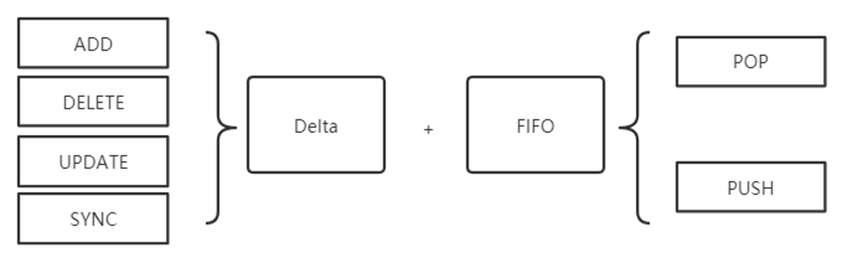
DeltaFIFO将接受来的资源event,转化为特定的变化类型,存储在队列中,周期性的POP出去,分发到事件处理器,并更新Indexer中的本地缓存。
Client-go定义了以下几种变化类型:
// 文件路径: k8s.io/client-go/tools/cache/delta_fifo.go
// DeltaType 其实是字符串类型的别名,代表一种变化
type DeltaType string
// Change type definition
const (
Added DeltaType = "Added" // 增
Updated DeltaType = "Updated" // 更新
Deleted DeltaType = "Deleted" // 删除
Replaced DeltaType = "Replaced" // 替换,list出错时,会触发relist,此时会替换
Sync DeltaType = "Sync" // 周期性的同步,底层会当作一个update类型处理
)
// Delta由一个对象+类型组成
type Delta struct {
Type DeltaType
Object interface{}
}
// Deltas是一组Delta
type Deltas []Delta然后我们看一下Delta_FIFO的实现
// 文件路径: k8s.io/client-go/tools/cache/delta_fifo.go
type DeltaFIFO struct {
// 读写锁与条件变量
lock sync.RWMutex
cond sync.Cond
// items是一个字典,存储了对象键与Delats的映射关系
// queue是一个FIFO队列,存储了先后进入队列的对象的对象键,queue里面的对象和items里的对象键是一一对应的
// items里的对象,至少有一个Delta
items map[string]Deltas
queue []string
// 通过Replace()接口将第一批对象放入队列,或者第一次调用增、删、改接口时标记为true
populated bool
// 通过Replace()接口将第一批对象放入队列的对象数量
initialPopulationCount int
// 用于计算对象键的方法
keyFunc KeyFunc
// 其实就是Indexer
knownObjects KeyListerGetter
// emitDeltaTypeReplaced is whether to emit the Replaced or Sync
// DeltaType when Replace() is called (to preserve backwards compat).
emitDeltaTypeReplaced bool
}可以用一张图简单描述下Delta_FIFO里面items和queue的关系:
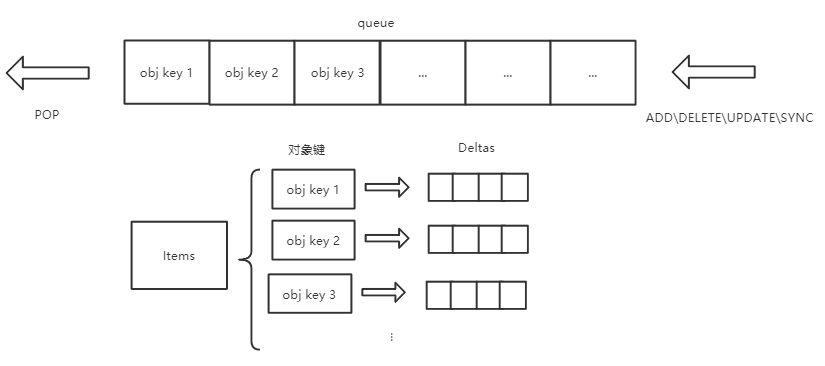
采用这样的结构把对象与事件的存储分离,好处就是不会因为某个对象的事件太多,而导致其他对象的事件一直得不到消费。
Delta_FIFO的核心操作有两个:往队列里面添加元素、从队列中POP元素,可以看一下这两个方法的实现:
// 文件路径: k8s.io/client-go/tools/cache/delta_fifo.go
// queueActionLocked 用于向队列中添加delta,调用前必须加写锁
// 传入delta类型、资源对象两个参数
func (f *DeltaFIFO) queueActionLocked(actionType DeltaType, obj interface{}) error {
// 获取资源对象的对象键
id, err := f.KeyOf(obj)
if err != nil {
return KeyError{obj, err}
}
// 向items中添加delta,并对操作进行去重,目前来看,只有连续两次操作都是删除操作的情况下,才可以合并,其他操作不会合并
newDeltas := append(f.items[id], Delta{actionType, obj})
newDeltas = dedupDeltas(newDeltas)
if len(newDeltas) > 0 {
// 向queue和items中添加元素
// 添加以后,条件变量发出消息,通知可能正在阻塞的POP方法有事件进队列了
if _, exists := f.items[id]; !exists {
f.queue = append(f.queue, id)
}
f.items[id] = newDeltas
f.cond.Broadcast()
} else {
// 冗余判断,其实是不会走到这个分支的,去重后的delta list长度怎么也不可能小于1
delete(f.items, id)
}
return nil
}
// Pop方法
func (f *DeltaFIFO) Pop(process PopProcessFunc) (interface{}, error) {
f.lock.Lock()
defer f.lock.Unlock()
for {
// 如果队列是空的,利用条件变量阻塞住,直到有新的delta
// 如果Close()被调用,则退出
// 否则一直循环处理
for len(f.queue) == 0 {
if f.closed {
return nil, ErrFIFOClosed
}
f.cond.Wait()
}
// 取队列第一个的所有deltas
id := f.queue[0]
f.queue = f.queue[1:]
if f.initialPopulationCount > 0 {
f.initialPopulationCount--
}
item, ok := f.items[id]
if !ok {
// Item may have been deleted subsequently.
continue
}
delete(f.items, id)
err := process(item)
// 如果处理失败了,调用addIfNotPresent,addIfNotPresent意为:如果queue中没有则添加
// 本身刚刚从queue和items中取出对象,应该不会存在重复的对象,这里调用addIfNotPresent应该只是为了保险起见
if e, ok := err.(ErrRequeue); ok {
f.addIfNotPresent(id, item)
err = e.Err
}
return item, err
}
}
3.3 Reflector
自下而上,到Reflector了。不记得Reflector是什么的,可以回到3.1前面看一下结构图。
K8s的设计是事件驱动的、充分微服务化的,我们可以从事件传递的角度重新理解一下K8s:
组件之间互相看作是事件的生产者、消费者,API Server看作是一个只用内存存储事件的Broker,我们可以从消息队列的角度取理解一下,如下图展示的:
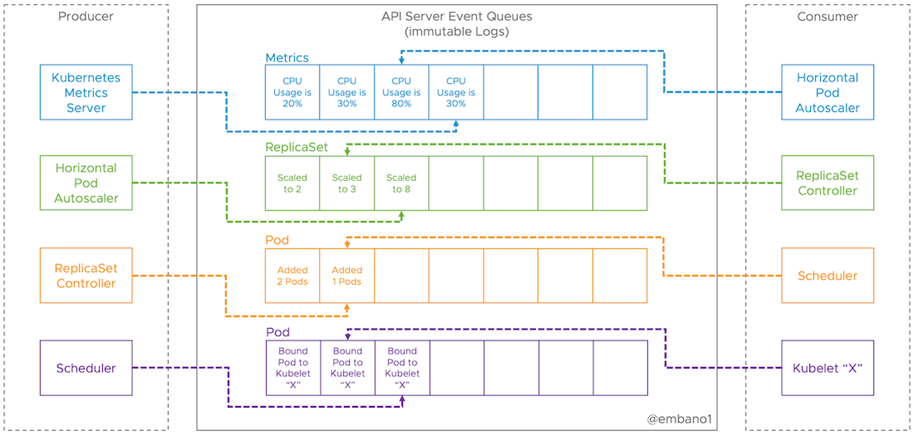
k8s服务端通过读取etcd的资源变更信息,向所有客户端发布资源变更事件。k8s中,组件之间通过HTTP协议进行通信,在不额外引入其他中间件的情况下,保证消息传递的实时性、可靠性、顺序性不是一个容易的事情。K8s内部所有的组件都是通过Informer机制实现与API Server的通信的。Informer直译就是消息通知者的意思。
通常一个Informer只会关注一种特定的资源,Reflector负责从API Server拉取&同步该资源类型下所有对象的event。例如,如果当前informer关注Pod资源,那么Reflector会首先list集群中所有的Pod的信息,同步本地的ResourceVersion,之后基于当前的ResourceVerison,使用一个Http长连接Watch集群中Pod资源的事件,并传递到Delta_FIFO模块。
Reflector字面意思就是反射器,我们可以看下Reflector的struct声明
// 文件路径: k8s.io/client-go/tools/cache/reflector.go
// Reflector监控某一种资源的变化,并将这些变化传递到存储中
type Reflector struct {
name string // 名字,默认会被命名为 文件:行号
expectedTypeName string // 被监控的资源的类型名
expectedType reflect.Type // 监控的对象类型
expectedGVK *schema.GroupVersionKind // The GVK of the object we expect to place in the store if unstructured.
store Store // 存储,就是Delta_FIFO,这里的Store类型实际是Delta_FIFO的父类
listerWatcher ListerWatcher // 用来进行list&watch的接口对象,大概知道做什么的就行了,底层是通过http长连接实现的资源监听
resyncPeriod time.Duration // 重新同步的周期
ShouldResync func() bool // 周期性的判断是否需要重新同步
clock clock.Clock // 时钟对象,主要是为了给测试留后门,方便修改时间
...
}
ResourceVersion是ETCD生成的全局唯一且递增的序号,通过此序号,客户端可以知道目前与服务端信息同步的状态,每次只取大于等于本地ResourceVersion的事件,好处是可以实现事件的全局唯一,实现“断点续传”功能,不用担心本地客户端偶尔出现的网络异常。
可以关注到Reflector三个比较关键的方法:
// 文件路径: k8s.io/client-go/tools/cache/reflector.go
// 反射器的入口方法,wait.Backoffutil会周期性的执行传入的匿名函数,直到接收到stopCh传来的终止信号
func (r *Reflector) Run(stopCh <-chan struct{}) {
klog.V(2).Infof("Starting reflector %s (%s) from %s", r.expectedTypeName, r.resyncPeriod, r.name)
wait.BackoffUntil(func() {
if err := r.ListAndWatch(stopCh); err != nil {
r.watchErrorHandler(r, err)
}
}, r.backoffManager, true, stopCh)
klog.V(2).Infof("Stopping reflector %s (%s) from %s", r.expectedTypeName, r.resyncPeriod, r.name)
}
// ListAndWatch方法比较长,这里截取部分展示,主要有三部分
// 1. list操作,更新本地的资源版本号,最先执行且只执行一次
// 2. 启动后台的周期性sync协程
// 3. 死循环执行watchHandler操作
func (r *Reflector) ListAndWatch(stopCh <-chan struct{}) error {
// 全量list的逻辑,只执行一次
// 这一步里面会将list返回的结果实例化为对象数组,也就是反射的过程,这也是reflector名字的由来,但是reflector目前做的不仅仅是反射
if err := func() error {
...
r.setIsLastSyncResourceVersionUnavailable(false) // list was successful
initTrace.Step("Objects listed")
listMetaInterface, err := meta.ListAccessor(list)
r.setLastSyncResourceVersion(resourceVersion)
initTrace.Step("Resource version updated")
return nil
}(); err != nil {
return err
}
// 后台定期sync协程,会一直周期性执行
go func() {
resyncCh, cleanup := r.resyncChan()
for {
...
cleanup()
resyncCh, cleanup = r.resyncChan()
}
}()
// watch操作
for {
...
if err := r.watchHandler(start, w, &resourceVersion, resyncerrc, stopCh); err != nil {
...
return nil
}
...
}
}
// 我们继续看看watchHandler里面做了什么
// 去掉了注释、日志、错误判断,只看核心逻辑,可以直观的看到,最后的处理逻辑落在了Delta_FIFO上
func (r *Reflector) watchHandler(start time.Time, w watch.Interface, resourceVersion *string, errc chan error, stopCh <-chan struct{}) error {
eventCount := 0
defer w.Stop()
loop:
for {
select {
case <-stopCh:
return errorStopRequested
case err := <-errc:
return err
case event, ok := <-w.ResultChan():
if !ok {
break loop
}
if event.Type == watch.Error {
return apierrors.FromObject(event.Object)
}
meta, err := meta.Accessor(event.Object)
newResourceVersion := meta.GetResourceVersion()
// 操作Delta_FIFO
switch event.Type {
case watch.Added:
err := r.store.Add(event.Object)
case watch.Modified:
err := r.store.Update(event.Object)
case watch.Deleted:
err := r.store.Delete(event.Object)
case watch.Bookmark:
default:
utilruntime.HandleError(fmt.Errorf("%s: unable to understand watch event %#v", r.name, event))
}
*resourceVersion = newResourceVersion
r.setLastSyncResourceVersion(newResourceVersion)
eventCount++
}
}
...
}可以总结一下Reflector:
- Reflector利用apiserver的client列举全量对象(版本为0以后的对象全部列举出来)
- 将全量对象同步到DeltaFIFO中,并且更新资源的版本号,后续watch会依赖此版本号;
- 在后台启动一个定时resync的协程,把全量对象以Update事件的方式通知出去(如果没有设置同步周期,这一步可以不执行);
- 基于当前资源版本号watch资源;
- 一旦有对象发生变化,那么就会根据变化的类型(新增、更新、删除)调用DeltaFIFO的相应接口,同时更新当前资源的版本号
3.4 Controller
Contoller是一个很暧昧的词,乍一听就知道这个是控制器,仔细一想又不知道它能控制什么玩意儿。K8s里面本身有各种资源Controller,和这里的含义不同。
如果认真看了前面的文档,会注意到,上面的结构图里,其实没有Controller这个组件,这个类更像是一个wrapper,将前面提到的Indexer、Delta_FIFO、Reflector组合在一起,Controller驱动所有环节一起运转起来。
上代码:
// 文件路径: k8s.io/client-go/tools/cache/controller.go
type controller struct {
// 所有的配置信息、组件
config Config
// reflector
reflector *Reflector
reflectorMutex sync.RWMutex
clock clock.Clock
}
// Controller 由成员变量Config进行配置驱动的控制器
type Controller interface {
// Run做了两件事:
// 1. 构造并运行Reflector从Config中的listAndWatcher中获取事件,并传递给Config中的Queue(其实就是Delta_FIFO)
// 2. 周期性的从Config的queue中pop数据,传递给Config中的ProcessFunc处理
// 如果stopCh传来信息,则终止上述操作
Run(stopCh <-chan struct{})
HasSynced() bool
LastSyncResourceVersion() string
}
type Config struct {
// DeltaFIFO
Queue
ListerWatcher
// 自定义的回调方法
Process ProcessFunc
// 期待处理的资源对象的类型
ObjectType runtime.Object
// 全量resync的周期
FullResyncPeriod time.Duration
// delta fifo周期性同步判断时使用
ShouldResync ShouldResyncFunc
...
}所以核心方法就是Run:
// 文件路径: k8s.io/client-go/tools/cache/controller.go
func (c *controller) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
go func() {
<-stopCh
c.config.Queue.Close()
}()
r := NewReflector(
c.config.ListerWatcher,
c.config.ObjectType,
c.config.Queue,
c.config.FullResyncPeriod,
)
r.ShouldResync = c.config.ShouldResync
r.clock = c.clock
if c.config.WatchErrorHandler != nil {
r.watchErrorHandler = c.config.WatchErrorHandler
}
c.reflectorMutex.Lock()
c.reflector = r
c.reflectorMutex.Unlock()
// wait.group的作用主要是等待所有关联的协程推出后才退出
var wg wait.Group
defer wg.Wait()
wg.StartWithChannel(stopCh, r.Run)
wait.Until(c.processLoop, time.Second, stopCh)
}
可以看到,除了reflector.Run,剩下的逻辑,都在processLoop方法中,reflector的run方法前面已经分析过了,不赘叙。看processLoop
func (c *controller) processLoop() {
for {
obj, err := c.config.Queue.Pop(PopProcessFunc(c.config.Process))
if err != nil {
if err == ErrFIFOClosed {
return
}
if c.config.RetryOnError {
// This is the safe way to re-enqueue.
c.config.Queue.AddIfNotPresent(obj)
}
}
}
}
这里看下来,可以发现其实也没有什么独特的逻辑,controller做的,就是把各个模块粘合起来。
结构图上,Indexer等几个组件都被框在Informer里,对应的类型就是SharedInformer。
一路分析下来,其实直到Contorller组件,都没有用到Indexer组件。SharedInformer是所有组件最终汇聚的地方。
我们可以看看SharedIndexInformr类型相关的声明:
type SharedInformer interface {
// 添加事件处理回调
AddEventHandler(handler ResourceEventHandler)
AddEventHandlerWithResyncPeriod(handler ResourceEventHandler, resyncPeriod time.Duration)
// 获取local storage 就是Indexer
GetStore() Store
// Run 入口方法
Run(stopCh <-chan struct{})
LastSyncResourceVersion() string
// 处理list & watch的异常
SetWatchErrorHandler(handler WatchErrorHandler) error
}
// 在SharedInformer基础上,添加Indexer相关的接口
type SharedIndexInformer interface {
SharedInformer
AddIndexers(indexers Indexers) error
GetIndexer() Indexer
}
// 具体的实现
type sharedIndexInformer struct {
indexer Indexer
controller Controller
// sharedProcesssor是一个事件处理器
processor *sharedProcessor
// 突变检测器,暂且不管
cacheMutationDetector MutationDetector
listerWatcher ListerWatcher
// 期望处理的k8s资源类型
objectType runtime.Object
// 字面意思,小于等于0则不check
resyncCheckPeriod time.Duration
defaultEventHandlerResyncPeriod time.Duration
clock clock.Clock
started, stopped bool
startedLock sync.Mutex.
blockDeltas sync.Mutex
watchErrorHandler WatchErrorHandler
}sharedIndexInformer的核心逻辑在Run方法中:
// 文件路径 k8s.io/client-go/tools/cache/shared_informer.go
func (s *sharedIndexInformer) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
fifo := NewDeltaFIFOWithOptions(DeltaFIFOOptions{
KnownObjects: s.indexer,
EmitDeltaTypeReplaced: true,
})
// 配置controller使用的Config
cfg := &Config{
Queue: fifo,
ListerWatcher: s.listerWatcher,
ObjectType: s.objectType,
FullResyncPeriod: s.resyncCheckPeriod,
RetryOnError: false,
ShouldResync: s.processor.shouldResync,
// 注意这里的Process,是从delta_fifo调用Pop方法时,调用的回调
Process: s.HandleDeltas,
WatchErrorHandler: s.watchErrorHandler,
}
func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.controller = New(cfg)
s.controller.(*controller).clock = s.clock
s.started = true
}()
// Separate stop channel because Processor should be stopped strictly after controller
processorStopCh := make(chan struct{})
var wg wait.Group
defer wg.Wait() // Wait for Processor to stop
defer close(processorStopCh) // Tell Processor to stop
// 新开协程启动processor、cacheMutationDetector
wg.StartWithChannel(processorStopCh, s.cacheMutationDetector.Run)
wg.StartWithChannel(processorStopCh, s.processor.run)
defer func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.stopped = true // Don't want any new listeners
}()
// 启动controller
s.controller.Run(stopCh)
}目前为止,我们还没有发现Delta_FIFO的事件都被谁消费了,HandleDeltas方法看起来大概率可以帮我们揭开谜底了:
// 文件路径 k8s.io/client-go/tools/cache/shared_informer.go
func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock()
// from oldest to newest
for _, d := range obj.(Deltas) {
switch d.Type {
case Sync, Replaced, Added, Updated:
s.cacheMutationDetector.AddObject(d.Object)
if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {
if err := s.indexer.Update(d.Object); err != nil {
return err
}
isSync := false
switch {
case d.Type == Sync:
// Sync events are only propagated to listeners that requested resync
isSync = true
case d.Type == Replaced:
if accessor, err := meta.Accessor(d.Object); err == nil {
if oldAccessor, err := meta.Accessor(old); err == nil {
// Replaced events that didn't change resourceVersion are treated as resync events
// and only propagated to listeners that requested resync
isSync = accessor.GetResourceVersion() == oldAccessor.GetResourceVersion()
}
}
}
s.processor.distribute(updateNotification{oldObj: old, newObj: d.Object}, isSync)
} else {
if err := s.indexer.Add(d.Object); err != nil {
return err
}
s.processor.distribute(addNotification{newObj: d.Object}, false)
}
case Deleted:
if err := s.indexer.Delete(d.Object); err != nil {
return err
}
s.processor.distribute(deleteNotification{oldObj: d.Object}, false)
}
}
return nil
}比较直观的看到,这个方法还是挺重要的,一方面这个方法衔接了controller里面的delta_fifo与sharedProcesser的事件分发distribute,另一方面,这个方法也衔接了delta_fifo与Indexer,在这里更新了本地缓存。
最后看一下sharedProcesser的distribute和processorListenor的run方法:
// 文件路径 k8s.io/client-go/tools/cache/shared_informer.go
// 分发事件
func (p *sharedProcessor) distribute(obj interface{}, sync bool) {
p.listenersLock.RLock()
defer p.listenersLock.RUnlock()
// 这里调用了`processorListenor`的add方法
if sync {
for _, listener := range p.syncingListeners {
listener.add(obj)
}
} else {
for _, listener := range p.listeners {
listener.add(obj)
}
}
}
// processorListenor
func (p *processorListener) run() {
stopCh := make(chan struct{})
// 每秒一次,拿新的事件,然后交给事件的回调函数处理
wait.Until(func() {
for next := range p.nextCh {
switch notification := next.(type) {
case updateNotification:
p.handler.OnUpdate(notification.oldObj, notification.newObj)
case addNotification:
p.handler.OnAdd(notification.newObj)
case deleteNotification:
p.handler.OnDelete(notification.oldObj)
default:
utilruntime.HandleError(fmt.Errorf("unrecognized notification: %T", next))
}
}
// the only way to get here is if the p.nextCh is empty and closed
close(stopCh)
}, 1*time.Second, stopCh)
}
到此为止,Informer机制下,服务端与客户端的交互分层逻辑比较清晰了:
- Reflector通过List&watch机制与API Server拉取信息
- 一级缓存+消息队列 Delta_FIFO缓存事件,分发到下游的事件处理器+二级缓存
Indexer - 二级缓存作为只读缓存,给客户端提供快速读取资源信息的能力
- 客户端处理事件回调、可以从二级缓存读取感兴趣的信息、可以向API Server发送资源对象的变更请求
以上是单个Informer的工作过程。
由于每个Informer内,都需要对API Server进行大量网络通信,对此,k8s采用单例模式来尽可能降低开销。如下的代码片段展示了sharedInformerFactory的结构,内置一个map变量,通过资源的类型来组织informers,保证每个二进制文件中,同一资源类型的informer,只能存在一个。
// 文件路径: k8s.io/client-go/informers/factory.go
type sharedInformerFactory struct {
client kubernetes.Interface
namespace string
tweakListOptions internalinterfaces.TweakListOptionsFunc
lock sync.Mutex
defaultResync time.Duration
customResync map[reflect.Type]time.Duration
informers map[reflect.Type]cache.SharedIndexInformer
// startedInformers is used for tracking which informers have been started.
// This allows Start() to be called multiple times safely.
startedInformers map[reflect.Type]bool
}使用informer的样例代码如下:
config, err := clientcmd.BuildConfigFromFlags("", clientcmd.RecommendedHomeFile)
mustSuccess(err)
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err)
}
sharedInformers := informers.NewSharedInformerFactory(clientset, 0)
stopChan := make(chan struct{})
defer close(stopChan)
informer := sharedInformers.Core().V1().Pods().Informer()
// 定制回调函数
informer.AddEventHandlerWithResyncPeriod(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
//mObj := obj.(v1.Object)
//fmt.Printf("new obj name: %s\n", mObj.GetName())
},
UpdateFunc: func(oldObj, newObj interface{}) {
timeStr := time.Now().Format("2006-01-02 15:04:05")
oObj := oldObj.(v1.Object)
nObj := newObj.(v1.Object)
//if nObj.GetResourceVersion() != oObj.GetResourceVersion() {
fmt.Printf("[%s] %s Pod Update to %s \n", timeStr, oObj.GetUID(), nObj.GetUID())
//}
},
DeleteFunc: func(obj interface{}) {
//Obj := obj.(v1.Object)
//fmt.Printf("Delete pod %s \n", Obj.GetName())
},
}, time.Second*30)
informer.Run(stopChan)
3.6 Work Queue
一开始的框架图中,其实还有一个部分没有提到,就是WorkQueue。
work queue并不完全是informer机制的一部分。相对Informer来说,是Client-go代码库中比较独立的一个组件。在开发并行程序时,需要频繁的进行数据同步,本身goLang拥有channel机制,但是不能满足一些复杂场景的需求。例如:延时队列、限速队列。
client-go中提供了多种队列以供选择,可以胜任更多的场景。
3.6.1 通用队列
通用队列的定义如下:
// 文件路径 k8s.io/client-go/util/workqueue/queue.go
type Interface interface {
Add(item interface{})
Len() int
Get() (item interface{}, shutdown bool)
Done(item interface{})
ShutDown()
ShuttingDown() bool
}
type Type struct {
// queue defines the order in which we will work on items. Every
// element of queue should be in the dirty set and not in the
// processing set.
queue []t
// dirty defines all of the items that need to be processed.
dirty set
// Things that are currently being processed are in the processing set.
// These things may be simultaneously in the dirty set. When we finish
// processing something and remove it from this set, we'll check if
// it's in the dirty set, and if so, add it to the queue.
processing set
cond *sync.Cond
shuttingDown bool
metrics queueMetrics
unfinishedWorkUpdatePeriod time.Duration
clock clock.Clock
}这个队列里面绝大多数内容挺好理解的,dirty这个set是一个特殊的设置。
我们可以看一下它核心的Add、Get、Done方法:
// 文件路径 k8s.io/client-go/util/workqueue/queue.go
// Add marks item as needing processing.
func (q *Type) Add(item interface{}) {
q.cond.L.Lock()
defer q.cond.L.Unlock()
if q.shuttingDown {
return
}
// 为什么用dirty来判断,而不用queue? 因为dirty是set,速度更快
if q.dirty.has(item) {
return
}
q.metrics.add(item)
// 同一个对象,processing和queue同时只能有一个拥有这个对象
// 如果一个对象正在被处理,此时又被添加进来了,那么先将其放进dirty中
q.dirty.insert(item)
if q.processing.has(item) {
return
}
q.queue = append(q.queue, item)
q.cond.Signal()
}
// 从queue中取出,放进processing,并从dirty中移除
func (q *Type) Get() (item interface{}, shutdown bool) {
q.cond.L.Lock()
defer q.cond.L.Unlock()
for len(q.queue) == 0 && !q.shuttingDown {
q.cond.Wait()
}
if len(q.queue) == 0 {
// We must be shutting down.
return nil, true
}
item, q.queue = q.queue[0], q.queue[1:]
q.metrics.get(item)
q.processing.insert(item)
q.dirty.delete(item)
return item, false
}
func (q *Type) Done(item interface{}) {
q.cond.L.Lock()
defer q.cond.L.Unlock()
q.metrics.done(item)
// 同一个对象,通常processing和dirty中只有一个
// 如果processing处理好了,发现dirty中还有一个,那么可以认为旧的任务已经过时了,新的还是需要重新处理一次,因此重新放入queue中
q.processing.delete(item)
if q.dirty.has(item) {
q.queue = append(q.queue, item)
q.cond.Signal()
}
}所以dirty的作用是?
- 快速去重,避免遍历queue
- queue的辅助结构
其他的功能就类似正常的队列。不赘叙。这里的逻辑有点绕,但是最终的效果是:
在等待处理的数据中,每一个对象只能存在一份,不能重复添加。
不过这里为什么这么设计,具体的场景,需要进一步的查看别的controller组件了。
3.6.2 延迟队列
延迟相比普通队列,多了一个等待循环和AddAfter方法,通过goLang的select+channel非常巧妙的实现了延迟添加的功能:
// 文件路径 k8s.io/client-go/util/workqueue/delaying_queue.go
func (q *delayingType) AddAfter(item interface{}, duration time.Duration) {
// don't add if we're already shutting down
if q.ShuttingDown() {
return
}
q.metrics.retry()
// immediately add things with no delay
if duration <= 0 {
q.Add(item)
return
}
select {
case <-q.stopCh:
// 前面都是一些判断逻辑处理
// 这里将数据包装成waitFor对象,然后添加到waitingForAddCh这个channel中
case q.waitingForAddCh <- &waitFor{data: item, readyAt: q.clock.Now().Add(duration)}:
}
}
// 顺带看看waitFor的实现
// 就是数据+期望时间
type waitFor struct {
data t
readyAt time.Time
// index in the priority queue (heap)
index int
}
// 等待循环
func (q *delayingType) waitingLoop() {
defer utilruntime.HandleCrash()
// Make a placeholder channel to use when there are no items in our list
never := make(<-chan time.Time)
// Make a timer that expires when the item at the head of the waiting queue is ready
var nextReadyAtTimer clock.Timer
waitingForQueue := &waitForPriorityQueue{}
heap.Init(waitingForQueue)
waitingEntryByData := map[t]*waitFor{}
for {
if q.Interface.ShuttingDown() {
return
}
now := q.clock.Now()
// Add ready entries
for waitingForQueue.Len() > 0 {
// 判断优先队列中的第一个元素,是否到期了
// 如果到期了,就取出来添加到队列中
entry := waitingForQueue.Peek().(*waitFor)
if entry.readyAt.After(now) {
break
}
entry = heap.Pop(waitingForQueue).(*waitFor)
q.Add(entry.data)
delete(waitingEntryByData, entry.data)
}
// Set up a wait for the first item's readyAt (if one exists)
nextReadyAt := never
if waitingForQueue.Len() > 0 {
if nextReadyAtTimer != nil {
nextReadyAtTimer.Stop()
}
entry := waitingForQueue.Peek().(*waitFor)
nextReadyAtTimer = q.clock.NewTimer(entry.readyAt.Sub(now))
nextReadyAt = nextReadyAtTimer.C()
}
select {
case <-q.stopCh:
return
case <-q.heartbeat.C():
// continue the loop, which will add ready items
case <-nextReadyAt:
// continue the loop, which will add ready items
// addAfter添加的元素最终会传递到这里,可以看到会将内容添加到waitingForQueue中,这个是一个根据时间排序的优先队列
case waitEntry := <-q.waitingForAddCh:
if waitEntry.readyAt.After(q.clock.Now()) {
insert(waitingForQueue, waitingEntryByData, waitEntry)
} else {
q.Add(waitEntry.data)
}
drained := false
for !drained {
select {
case waitEntry := <-q.waitingForAddCh:
if waitEntry.readyAt.After(q.clock.Now()) {
insert(waitingForQueue, waitingEntryByData, waitEntry)
} else {
q.Add(waitEntry.data)
}
default:
drained = true
}
}
}
}
}
延迟队列的添加过程如下所示,通过AddAfter方法,将对象数据与期望添加的时间包装成WaitFor对象传递到waitingForAddCh这个channel中,然后另一个协程中运行的waitingLoop中会捕获该数据,放入优先队列:
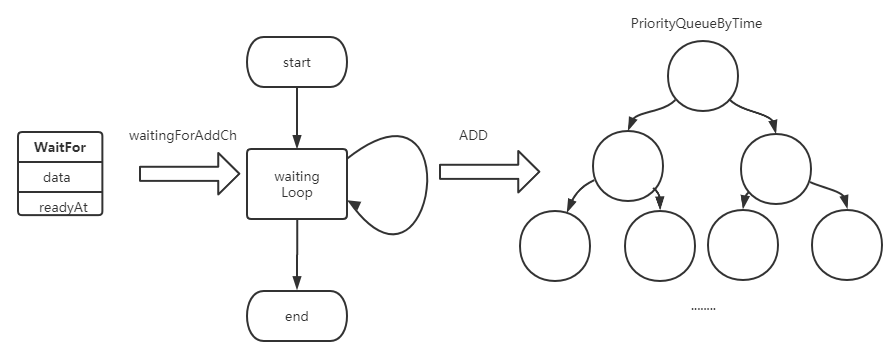
然后同样在waitingLoop中,会轮询的检测优先队列的top元素是否到达既定的时间,如果到了,则pop元素并添加到FIFO中:
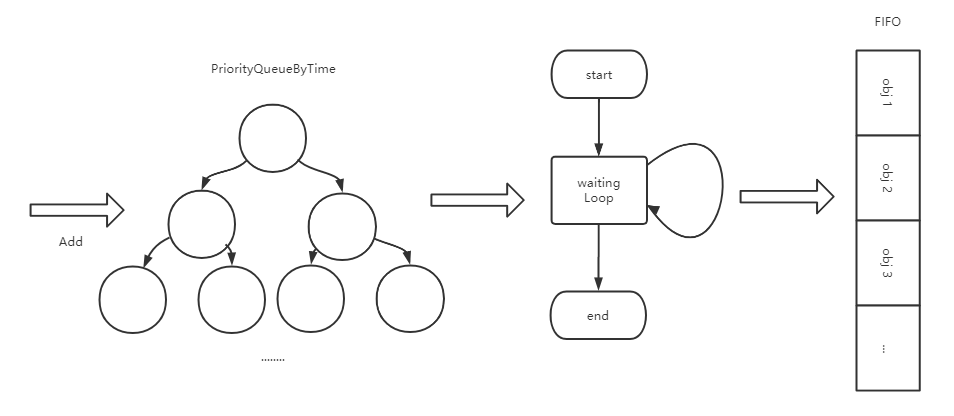
所以可以看出来延迟队列的关键在于:
- 时间优先队列(heap结构的,篇幅有限,不赘叙)
- 等待循环
3.6.3 限速队列
限速队列的应用很广泛,常见场景有:
- 失败后重试,例如:第一次失败,隔1秒重试,第二次失败,隔2秒,其实就是一种限速
- 限制平均QPS,避免处理不过来,被瞬时流量打爆
除了客户端,nginx这些服务器软件上也应用颇多,主要是流量控制上。
首先看下限速队列的通用类型
// 文件路径 k8s.io/client-go/util/workqueue/rate_limiting_queue.go
// RateLimitingInterface 接口
type RateLimitingInterface interface {
// 继承自延迟队列的接口
DelayingInterface
// 直到限速器允许添加后,才添加进队列
AddRateLimited(item interface{})
// 释放指定元素,清空该元素的排队数
Forget(item interface{})
// 获取指定元素的排队数
NumRequeues(item interface{}) int
}
// rateLimitingType 类型实现了延迟队列和限速器的方法
type rateLimitingType struct {
DelayingInterface
rateLimiter RateLimiter
}
func (q *rateLimitingType) AddRateLimited(item interface{}) {
q.DelayingInterface.AddAfter(item, q.rateLimiter.When(item))
}
func (q *rateLimitingType) NumRequeues(item interface{}) int {
return q.rateLimiter.NumRequeues(item)
}
func (q *rateLimitingType) Forget(item interface{}) {
q.rateLimiter.Forget(item)
可以看到这里限速队列的操作和延迟队列类似,通过限速器获取当前元素需要排队的时间,然后转化为延迟队列来处理。
那么限速器的实现呢?
// 文件路径 k8s.io/client-go/util/workqueue/default_rate_limiters.go
// 限速器的通用接口
type RateLimiter interface {
// When 获取当前对象多久可以被添加进队列
When(item interface{}) time.Duration
// Forget 释放当前对象,取消当前对象的排队
Forget(item interface{})
// NumRequeues 返回当前对象失败的次数
NumRequeues(item interface{}) int
}限速器具体的实现有四种:
1. 令牌桶算法 BucketRateLimiter
令牌桶算法是通过发令牌的频率,来控制流量的速度的。
这里提一下,最基础的限流算法是漏桶算法,也是nginx默认使用的限流算法,漏桶算法的原理是,假设流量源源不断的往一个桶里面流入,并且以一定的速度流出桶,桶的容量有限。漏桶算法的原理很简单,达到的效果就是,流量进入系统的平均速度永远不会超过桶漏水的速度。超过桶容量的流量会被丢弃。漏桶算法的缺点没有考虑流量的“峰谷”效应。(nginx使用的是改进版的漏桶算法,这里不赘叙)。
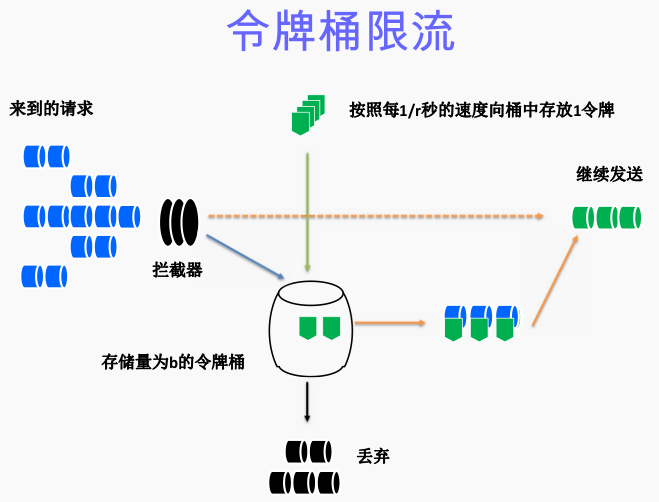
令牌桶算法则允许流量一定程度的爆发(burst),令牌桶算法的原理:
- 以固定的速率发放令牌
- 流量想要进入系统,必须获得一个令牌,否则无法进入
- 在流量较小时,令牌消耗不掉会积累起来
- 在流量较大时,即便流量流入的速度短时间大于发令牌的速度,只要还有库存的令牌,那么流量也可以进入系统;
令牌桶算法的效果:在整个时间线上,流量的平均流入速度不会超过令牌的发放速度,但是系统允许短时间的流量爆发,此时,系统处理的流量会大于令牌的发放速度。
假设,r参数表示每秒往“桶”里填充的token数量,b参数表示令牌桶的大小(即令牌桶最多存放的token数量)。我们假定r为10,b为100。在一个限速周期内插入了1000个元素,那么前b(即100)个元素会被立刻处理,而后面元素的延迟时间分别为100/100ms、101/200ms、102/300ms、103/400ms,以此类推。
这也就是方法when返回预期时间的原理。
网上找了一个令牌桶算法的原理图
2. 排队指数算法 ItemExponentialFailureRateLimiter
排队指数算法将相同元素的排队数作为指数,排队数增大,速率限制呈指数级增长,但其最大值不会超过maxDelay。元素的排队数统计是有限速周期的,一个限速周期是指从执行AddRateLimited方法到执行完Forget方法之间的时间。如果该元素被Forget方法处理完,则清空排队数。
计算延迟时间的方法如下:
// 文件路径 k8s.io/client-go/util/workqueue/default_rate_limiters.go
func (r *ItemExponentialFailureRateLimiter) When(item interface{}) time.Duration {
r.failuresLock.Lock()
defer r.failuresLock.Unlock()
exp := r.failures[item]
r.failures[item] = r.failures[item] + 1
// The backoff is capped such that 'calculated' value never overflows.
backoff := float64(r.baseDelay.Nanoseconds()) * math.Pow(2, float64(exp))
if backoff > math.MaxInt64 {
return r.maxDelay
}
calculated := time.Duration(backoff)
if calculated > r.maxDelay {
return r.maxDelay
}
return calculated
}3. 计数器算法(ItemFastSlowRateLimiter)
计数器算法是限速算法中最简单的一种,其原理是:限制一段时间内允许通过的元素数量,例如在1分钟内只允许通过100个元素,每插入一个元素,计数器自增1,当计数器数到100的阈值且还在限速周期内时,则不允许元素再通过。但WorkQueue在此基础上扩展了fast和slow速率。计数器算法提供了4个主要字段:failures、fastDelay、slowDelay及maxFastAttempts。其中,failures字段用于统计元素排队数,每当AddRateLimited方法插入新元素时,会为该字段加1;而fastDelay和slowDelay字段是用于定义fast、slow速率的;另外,maxFastAttempts字段用于控制从fast速率转换到slow速率。
// 文件路径 k8s.io/client-go/util/workqueue/default_rate_limiters.go
func (r *ItemFastSlowRateLimiter) When(item interface{}) time.Duration {
r.failuresLock.Lock()
defer r.failuresLock.Unlock()
r.failures[item] = r.failures[item] + 1
if r.failures[item] <= r.maxFastAttempts {
return r.fastDelay
}
return r.slowDelay
}4. 混合模式(MaxOfRateLimiter)
K8s默认的限速器采用的混合模式,混合模式的限速器里面包含了多个限速器,计算延迟时间时,遍历所有的限速器,以最大的限速时间作为当前的延迟时间,从而实现最严格的限速。
// 文件路径 k8s.io/client-go/util/workqueue/default_rate_limiters.go
// 默认的限速器就是采用混合模式
// 将 排队指数与令牌桶限速相混合
func DefaultControllerRateLimiter() RateLimiter {
return NewMaxOfRateLimiter(
NewItemExponentialFailureRateLimiter(5*time.Millisecond, 1000*time.Second),
// 10 qps, 100 bucket size. This is only for retry speed and its only the overall factor (not per item)
&BucketRateLimiter{Limiter: rate.NewLimiter(rate.Limit(10), 100)},
)
}
// 混合模式的延迟计算,取的是所有限速器的延迟最大值
func (r *MaxOfRateLimiter) When(item interface{}) time.Duration {
ret := time.Duration(0)
for _, limiter := range r.limiters {
curr := limiter.When(item)
if curr > ret {
ret = curr
}
}
return ret
}以上就是client-go里面主要功能组件的代码与原理分析。
4. 基于Client-go的二次开发Demo
4.1 解决第一个小问题 Event收集:
Event是k8s内置的一种对象资源,记录了集群中发生的各种事情,是重要的排错依据,但是因为集群中Event的量很大,如果全部存进ETCD里,会带来很大的性能和容量压力,所以ETCD默认只会存1个小时的Event。我们通过上面的学习,其实可以自己写一个小程序,来读取集群中的Event资源,写入到ES里,以实现比较灵活的监控。
这里我直接在client-go代码库的根目录下新建一个main/main.go,具体实现如下:
package main
import (
"bytes"
"context"
"fmt"
"github.com/elastic/go-elasticsearch/v7"
"github.com/elastic/go-elasticsearch/v7/esapi"
"k8s.io/api/events/v1beta1"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/apimachinery/pkg/util/json"
"k8s.io/client-go/informers"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/cache"
"k8s.io/client-go/tools/clientcmd"
"math/rand"
"strconv"
"time"
)
func mustSuccess(err error) {
if err != nil {
panic(err)
}
}
func esinsert(str []byte){
cfg := elasticsearch.Config{
Addresses: []string{
"http://es服务器的ip端口"
},
Username: "djf",
Password: "xxxxxx",
}
es, _ := elasticsearch.NewClient(cfg)
req := esapi.CreateRequest{
Index: "index-demo",
DocumentType: "_doc",
DocumentID: strconv.FormatInt(time.Now().Unix(),10) + strconv.Itoa(rand.Int()),
Body: bytes.NewReader(str),
}
res, err := req.Do(context.Background(), es)
defer res.Body.Close()
if err!=nil {
fmt.Println(res.String())
}
}
func main() {
config, err := clientcmd.BuildConfigFromFlags("", clientcmd.RecommendedHomeFile)
mustSuccess(err)
clientset, err := kubernetes.NewForConfig(config)
mustSuccess(err)
sharedInformers := informers.NewSharedInformerFactory(clientset, 0)
stopChan := make(chan struct{})
defer close(stopChan)
eventInformer := sharedInformers.Events().V1beta1().Events().Informer()
addChan := make(chan v1beta1.Event)
eventInformer.AddEventHandlerWithResyncPeriod(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
unstructObj, err := runtime.DefaultUnstructuredConverter.ToUnstructured(obj)
mustSuccess(err)
event := &v1beta1.Event{}
err = runtime.DefaultUnstructuredConverter.FromUnstructured(unstructObj, event)
mustSuccess(err)
addChan <- *event
},
UpdateFunc: func(oldObj, newObj interface{}) {
},
DeleteFunc: func(obj interface{}) {
},
}, 0)
go func() {
for {
select {
case event := <- addChan:
str, err := json.Marshal(&event)
mustSuccess(err)
esinsert(str)
break
}
}
}()
eventInformer.Run(stopChan)
}
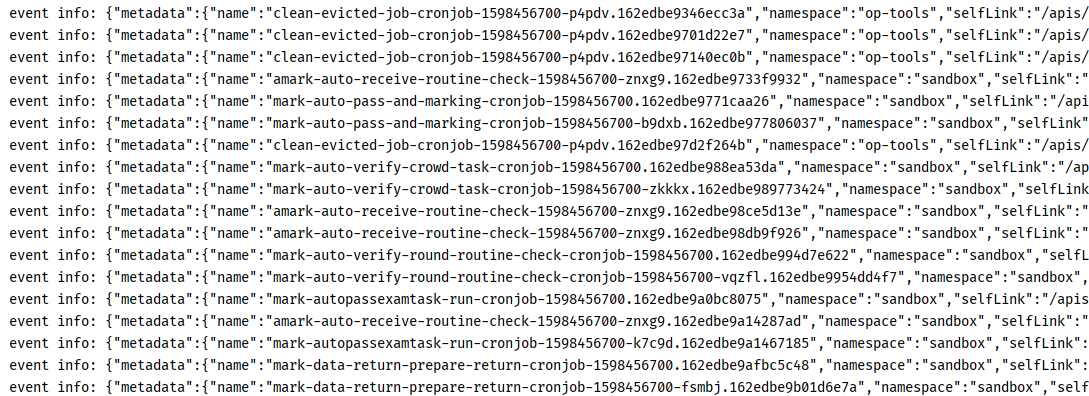
go run main.go,提取的Event信息:
4.2 解决第二个小问题 指定node上的pod数监控
假定我们需要观测某个node上面pod数量,结合之前的部分,我们可以通过自定义indexer,快速方便的获取到相关的数量,同时不需要额外的网络开销:
func podNumOfSpecifyNode() {
indexByPodNodeName := func(obj interface{}) ([]string, error) {
pod, ok := obj.(*apiCoreV1.Pod)
if !ok {
return []string{}, nil
}
if len(pod.Spec.NodeName) == 0 || pod.Status.Phase == apiCoreV1.PodSucceeded || pod.Status.Phase == apiCoreV1.PodFailed {
return []string{}, nil
}
return []string{pod.Spec.NodeName}, nil
}
config, err := clientcmd.BuildConfigFromFlags("", clientcmd.RecommendedHomeFile)
mustSuccess(err)
clientset, err := kubernetes.NewForConfig(config)
mustSuccess(err)
sharedInformers := informers.NewSharedInformerFactory(clientset, 0)
podInformer := sharedInformers.Core().V1().Pods().Informer()
podInformer.GetIndexer().AddIndexers(cache.Indexers{
"nodeName": indexByPodNodeName,
})
stopChan := make(chan struct{})
defer close(stopChan)
go podInformer.Run(stopChan)
for range time.Tick(time.Millisecond*1000){
podInformer.GetIndexer().ListKeys()
nodeName := "10.157.6.25"
podList, err := podInformer.GetIndexer().ByIndex("nodeName", nodeName)
mustSuccess(err)
fmt.Printf("%s 上面有 %v 个pod处于Running或Pending中:\n", nodeName, len(podList))
}
}
func main() {
podNumOfSpecifyNode()
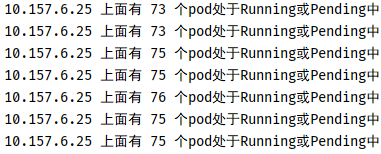
}运行效果:
每隔一秒会周期性的打印出目前10.157.6.25上面的pod数量
综上所述,就是client-go中大部分组件的分析;以及二次开发的demo。如果觉得本文有帮助到你,欢迎扫码关注:

发表回复
要发表评论,您必须先登录。