
Contents
k8s源码分析 2: kube-scheduler
1. 调度器简介
我们的系统设计,在设计抽象上往往都是在不同的层次上重复自己。
了解调度方式的演变过程,更有利于我们理解目前的调度功能的设计。
最早的调度器是单机系统里的批处理调度器,通过对计算机资源的分时复用来增加资源的利用率。
之后,某些场景下,我们需要能够及时响应外界的需求,缩短响应时间,因此发展出real-time 实时操作系统(例如国内开源的RT-thread操作系统),实时操作系统的调度器,需要能够低延迟的响应外部信号。
最终,目前我们的主流操作系统,会以批处理的方式调度任务,又通过中断等机制提供实时性的保证,通过灵活的调度策略,在吞吐量和延迟时间中获取平衡。
单机调度器的演变,可以总结出调度器设计的三个基本需求:
- 资源的有效利用
- 信号的实时响应
- 调度策略的灵活配置
这三个需求,某些场景下会相互掣肘,很难同时满足。
相比单机系统,在分布式系统中,还存在以下的一些困难:
- 集群资源状态同步:单机系统里,利用共享内存和锁机制可以很好的实现资源状态同步,保证任务的并发运行。但是在分布式系统中,网络通讯的不可靠性,使得在所有机器上达成状态的一致性非常困难。我们甚至不能保证所有机器上基准时钟的一致性。
- 容错性问题:单机系统里,任务规模、资源规模有限,出错的概率和成本比较低,但是分布式系统集群规模可能非常大,任务之间的依赖关系更加复杂,出错的概率大大增加,出现错误以后,恢复的成本也很高。调度器层面,对于错误的识别和恢复能力要足够快速准确。
- 可扩展性:分布式系统里,任务的类型远比单机系统下要多,不同任务的调度需求是不同的,一套调度器很难适应所有情况,同时待调度的资源规模不断扩大,可能存在上千、上万个节点;一方面要应对资源的不稳定,一万个节点,每天故障一个是很正常的概率,另一方面,要处理多元的调度需求,对调度器的可扩展性提出了很高的需求。
谷歌的论文《Omega: flexible, scalable schedulers for large compute clusters 》里把分布式系统的调度器分为了三种类型,这里简单介绍下。
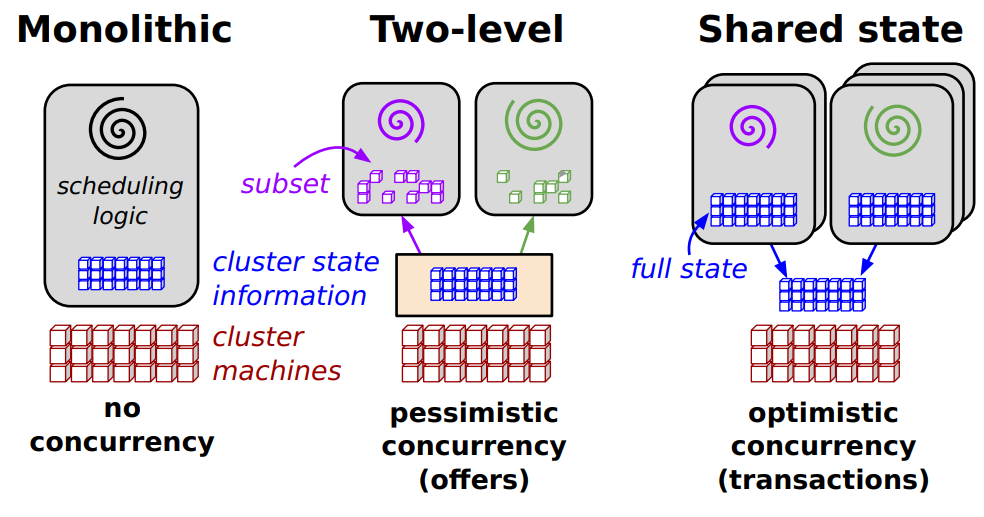
1.1 宏调度 monolithic
宏调度器也叫集中式调度器;这种调度类型的特点是:一个集群里,只有一个调度器实例、一套调度逻辑,没有并行,常见于小规模集群、单机上的HPC(high performance computing)调度中。这类调度器中,资源的使用状态和任务的执行状态都由中央调度器管理。
集中式的调度器的特点:
- 适合批处理任务和吞吐量较大、运行时间较长的任务
- 调度算法只能全部内置在核心调度器当中,灵活性和策略的可扩展性不高
- 状态同步比较容易且稳定,这是因为资源使用和任务执行的状态被统一管理,降低了状态同步和并发控制的难度
- 由于存在单点故障的可能性,集中式调度器的容错性一般,有些系统通过热备份 Master 的方式提高可用性
- 由于所有的资源和任务请求都要由中央调度器处理,集中式调度器的可扩展性较差,容易成为分布式系统吞吐量的瓶颈
目前采用该方式的调度器:
- 单机操作系统:windows、Linux、macOS
- Hadoop YARN Resource Manager + Node Manager + Application manager
现在的分布式系统中,一般会存在多个stand-by调度器实例,用于替补主调度器实例。降低单点故障的影响。
1.2 两层式调度 two-level
集中式调度器的缺点在于可扩展性比较差,容错性比较低,容易出现性能瓶颈。
通过资源层面的分区+分层,可以解决这些问题,这就是两层式调度的解决思路:
在双层调度器当中,资源的使用状态同时由分区调度器和中央调度器管理,但是中央调度器一般只负责宏观的大规模的资源分配, 因此业务压力较小。分区调度器负责管理自己分区的所有资源和任务,一般只有当所在分区资源无法满足需求时, 才将任务冒泡到中央调度器处理。
相比集中式调度器,双层调度器某一分区内的资源分配和工作安排可以由具体的任务本身进行定制, 因此大大增强了使用的灵活性,可以同时对高吞吐和低延迟的两种场景提供良好的支持。每个分区可以独立运行, 降低了单点故障导致系统崩溃的概率,增加了可用性和可扩展性。但是反过来也导致状态同步和维护变得比较困难。
思路很清晰,但是实现上,细节上有很多变化。
两层式调度器的例子:
- Golang runtime的Groroutine 协程调度器。在这一模型下,一个进程内部的资源就相当于一个分区,分区内的资源由运行时提供的调度器预先申请并自行管理。 运行时环境只有当资源耗尽时才会向系统请求新的资源,从而避免频繁的系统调用。
- Mesos。Mesos会把资源进行分区,一个区对应一个framework,在framework内部,由framework自行决定资源的分配与任务的调度,而framework整体,会向Mesos调取器申请资源。
- spark drizzle。原本spark使用一个集中式的调度器来调度和执行基于DAG模型的计算任务。Driver 向 Scheduler申请资源,然后由节点上的Executor进程负责任务的执行。后续为了优化流计算过程中调度器带来的延迟问题,改使用两层的调度模型。
Mesos是在k8s之前,应用的最广泛的调度系统,也是谷歌那篇论文里,重要的比对对象,它的调度原理,在《Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center 》论文里有详细的说明。目前公开的mesos支持的最大的集群规模达到数万台机器节点(推特内部的生产环境,约8万台机器)。
略微展开一下,Mesos内部的调度过程:
- 与一般通过 Master 请求资源不同,Mesos 提出了 Framework 的概念,每个 Framework 相当于一个独立的调度器(例如spark,yarn), 可以实现自己的调度策略
- Resource Offer机制。Master 掌握对整个集群资源的的状态,通过 Offer (而不是被动请求) 的方式通知每个 Framework 可用的资源有哪些。
- Resource Accept。Framework 根据自己的需求决定要不要占有 Master Offer 的资源,如果占有了资源,这些资源接下来将完全由 Framework 管理
- Framework 通过灵活分配自己占有的资源调度任务并执行,这一步就与Mesos无关了
注意,这里Mesos的资源是主动给出去的,不是被动的等framework来申请,而是主动的把资源定期推送给framework,共framework选择,framework有任务执行,资源不足时,并不能主动申请,只有接受到offer的时候,才可以挑选适合的资源来接受(Accept),剩余的offer就拒绝掉(reject),如果一直没有合适的资源,就会等下一轮master提供的offer。
Mesos这样的resource offer机制,有一些不足:
- 发offer的过程是悲观并发的(就和谷歌论文里的图也提到了),同一时间只会给一个framework提供offer,任何一个framework的决策效率会影响整个集群的决策效率。这点可以通过设置决策超时时间来规定一个上线,但是治标不治本。
- 推送机制,会导致很多无效的推送。不是所有framework都需要资源,但是mesos master并不能感知到这一点。这一点可以通过framework自己的状态来避免,比如通过一个标注位来标记自己此刻不缺资源。
其实mesos在选择哪些framework发offer的机制上,是有一套自己的算法的,这里就不赘述了。根据mesos上面论文中自己的描述,mesos比较适合调度短任务,因为他们认为在企业里,数据中心的资源百分之80都是被短任务消耗调的(数据实时查询、日志流式计算、大数据计算),有多短呢?论文里给了一个数据:
Most jobs are short (the median being 84s long), and the jobs are composed of fine-grained map and reduce tasks (the median task being 23s)
结合前面的内容,调度器要做的事情有两个:
- 追踪系统里资源分配和使用的状态
- 根据资源状态,调度任务,追踪任务执行的状态
在集中式调度器里,这两个状态都由中心调度器管理,并且一并集成了调度功能。
双层调度器模式里,这两个状态分别由中央调度器和次级调度器管理。
集中式调度器可以容易地保证全局状态的一致性但是可扩展性不够, 双层调度器对共享状态的管理较难达到好的一致性保证,也不容易检测资源竞争和死锁。
在此基础上,谷歌提出了共享状态调度的概念。
这种架构基本上沿袭了集中式调度器的模式,通过将中央调度器肢解为多个服务以提供更好的伸缩性。 这种调度器的核心是共享的集群状态,因此可以被称为共享状态调度器。
Omega在状态的管理里,引入了事务的概念。如果将数据库储存的数据看作共享状态, 那么数据库就是是共享状态管理的最成熟、最通用的解决方案!事务更是早已被开发者们熟悉而且证明非常成熟和好用的并发抽象。
Omega 将集群中资源的使用和任务的调度看作数据库中的条目,在一个应用执行的过程当中, 调度器可以分步请求多种资源,当所有资源依次被占用并使任务执行完成,这个 Transaction 就会被成功 Commit。
Omega 的设计借鉴了很多数据库设计的思路,比如:
- Transaction 设计保留了一般事务的诸多特性,如嵌套 Transaction 或者 Checkpoint。 当资源无法获取或任务执行失败,事务将会被回滚到上一个 Checkpoint 那里
- Omega 可以实现传统数据库的死锁检测机制,如果检测到死锁,可以安全地撤销一个任务或其中的一些步骤
- Omega 使用了乐观锁,也就是说申请的资源不会立刻被加上排他锁,只有需要真正分配资源或进行事务提交的时候才会检查锁的状态, 如果发现出现了 Race Condition 或其他错误,相关事务可以被回滚
- Omega 可以像主流数据库一样定义 Procedure ,这些 Procedure 可以实现一些简单的逻辑, 用于对用户的资源请求进行合法性的验证(如优先级保证、一致性校验、资源请求权限管理等)
直观的体验就是:借助事务机制,Omega对于状态的管理更加游刃有余,且随着分布式数据库与分布式事务的发展和成熟,可行性问题也得到了解决。
Omega的缺点也很明显:实现起来非常复杂。
那么,说了这么多,各位觉得,kubernetes的调度器,属于上面的哪一种调度方式?
2. kube-scheduler功能回顾
简单了解了调度器的架构简史,回到k8s调度器本身,在研究它的实现之前,首先需要从功能上对它有一个基本的认识。
这里我们所说的功能,都是指k8s默认调度器的功能。
kubernetes里,调度的最小单元是Pod。每个pod的配置里,都指定了资源的最小值与最大值。每个机器节点都相当于一个资源池,供pod消耗。
所以k8s里,调度器最简单的需求就是:给待调度的pod找到一个符合它最低资源需要的node。
进一步,默认的资源字段里只提供了CPU和Memory,而一些pod会有比较特殊的资源需求,举个例子:GPU资源、本地化的存储资源需求。这类资源目前在默认的k8s集群里,没有量化索取的方式,只能通过给node打标签来标记node,然后在pod上设置nodeselector字段,进行节点过滤。
但是打标签的方式还是不够灵活,在正常的语义里,我们在筛选时,可以有两种强弱关系:必须(不)、可以(不)。打标签只能提供必须(不)的语义,不能提供should的语义,因此,又产生了另一种方式:NodeAffinity 节点亲和性。
亲和性调度,有两个选项:
- RequiredDuringSchedulingIgnoredDuringExecution: 类似nodeSelector的硬性限制,必须被满足的条件
- PreferredDuringSchedulingIgnoredDuringExecution: 强调优先满足指定规则,相当于软限制,多个优先级规则还可以设置权重,以定义执行的先后顺序;IgnoredDuringExecution的意思是: 如果一个Pod所在的节点在Pod运行期间标签发生了变更, 不再符合该Pod的节点亲和性需求, 则系统将忽略Node上Label的变化, 该Pod能继续在该节点运行
并且,
- 如果同时定义了nodeSelector和nodeAffinity,必须两个条件都满足才能调度
- 如果nodeAffinity指定了多个nodeSelectorTerms,匹配其中一个即可
- 一个nodeSelectorTerm中有多个matchExpressions,则都满足才行调度
亲和性是根据pod的情况,看node是否符合被调度的需要,反过来,node也可以表明自己拒绝某些pod的调度,这就是污点(Taints)和容忍(Tolerations)机制:
- node上可以设置某些taints,即污点
- pod上可以设置tolerations(容忍),标记自己可以容忍某些污点
只有Pod明确声明能够容忍这些污点, 否则无法在Node上运行。 Toleration是Pod的属性,让Pod能够(注意,只是能够,而非必须)运行在标注了Taint的Node上。
这里,调度器需要考虑node的nodeSelector与亲和性、反亲和性、污点需要。也就是需要考虑node与pod之间的关系。
再进一步,除了要考虑pod与node之间的关系,pod与pod之间本身也会存在错综复杂的关系。例如,同一个应用的pod尽量分散部署,避免单点故障,数据处理中,同一类批处理任务为了满足本地性的需要,可以部署在同一个节点上。
这个需求,可以通过Pod Affinity、antiAffinity来实现,也就是pod的亲和性、反亲和性。和节点亲和性含义类似,打字太累,这里感兴趣的自己去看吧。
所以,调度器需要满足pod亲和、反亲和的需要。
以上,就是一个调度器必须具备的基本功能了,但是还不够,还有一类异常情况没有考虑:集群资源不足时,怎么调度?
这也是调度器最后一块功能需求:驱逐(eviction)和抢占(Preemption)。
我们可以定义优先等级,并给pod打上标记,某些pod是高优先的,哪些是次要的,这一步仅仅依赖调度器不太行了:
- 驱逐eviction:由kubelet来负责,很好理解,kubelet守土有责,自己的节点资源不够了,就会看哪个pod是低优的,主动把他干掉。scheduler只负责调度,不负责调度后擦屁股,所以驱逐也没法让调度器去处理,从职责分离的角度去考虑,这样安排也是合理的。
- 抢占Preemption:这一步发生在调度阶段,如果调度器在调度一个pod的时候,发现没有足够的资源满足该pod,调度器就会重新审视目前现有的pod,比较正在运行的pod与当前待调度pod的优先级,如果当前的pod优先级更高,调度器就会发起抢占操作。
所以,调度器最后一个需求就是:资源不足情况下的抢占操作。
罗里吧嗦一堆,汇总一下默认调度器具有的功能:
- 给待调度的pod找到一个符合它最低资源需要的node。
- 调度器需要考虑pod与node之间的关系
- 调度器需要考虑pod与node上正在运行的pod之间的关系
- 资源不足的情况下,抢占现有低优先级pod的资源
后面可以结合代码实现看每一个需求是怎么满足的。
3. kube-scheduler源码分析
3.1 代码层次
和上次分析的client-go不同,调度器是k8s的一个组件,最终会编译出一个实际的二进制可执行文件,而client-go只是一个基础库。后续还会有别的k8s组件,所以,我们可以观察一下这些组件在代码结构上的一些共性。
k8s所有组件在代码上,都是交互与核心实现分离的,k8s在实现上需要足够的配置化,所以启动时,会通过命令行参数传入大量配置信息,因此,需要在命令行交互上足够强大且用户友好,这里仅仅依赖golang官方的flag库也不太够了,k8s引入了第三方的命令行交互库github.com/spf13/cobra。
这类负责交互的代码路径在kubernetes/cmd/下:
定位到kubernetes/cmd/kube-scheduler/scheduler.go文件:
// 文件路径:cmd/kube-scheduler/scheduler.go
func main() {
rand.Seed(time.Now().UnixNano())
command := app.NewSchedulerCommand()
// TODO: once we switch everything over to Cobra commands, we can go back to calling
// utilflag.InitFlags() (by removing its pflag.Parse() call). For now, we have to set the
// normalize func and add the go flag set by hand.
pflag.CommandLine.SetNormalizeFunc(cliflag.WordSepNormalizeFunc)
// utilflag.InitFlags()
logs.InitLogs()
defer logs.FlushLogs()
if err := command.Execute(); err != nil {
os.Exit(1)
}
}感兴趣的,可以去看下,几乎所有组件的启动main方法都是如此:
- 设置系统随机数引擎
- 设置命令行参数归一化方法
- 初始化log组件
- 调用command的Execute接口进行实际的执行
如果进一步,会看到这个command的Execute方法实际会调用scheduler.Run()方法。记住这一点,后面再看。
cmd路径下的代码主要负责一些交互、参数校验、初始化的操作;而调度器的核心实现则在pkg/scheduler路径下:
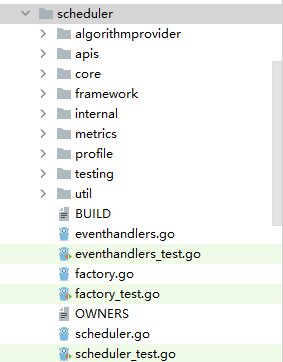
这边我看下来,各个目录的作用分别是:
1. algorithmprovider: 调度算法的注册与获取功能,核心数据结构是一个字典类的结构
2. apis: k8s集群中的资源版本相关的接口,和apiversion、type相关的一些内容
3. core: 调度器实例的核心数据结构与接口以及外部扩展机制的实现
4. framework: 定义了一套调度器内部扩展机制
5. internal: 调度器核心实例依赖的内部数据结构
6. metrics: 指标度量
7. profile: 基于framework的一套调度器的配置,用于管控整个调度器的运行框架
8. testing: 一些测试代码
9. util: 一些通用的工具
下面会以分-总的结构,对调度器的具体实现进行介绍,先介绍各个模块的实现,最后串起整个调度器的逻辑。
3.2 调度队列
显而易见的,几乎每一种调度器内部,都离不开队列这个数据结构,而且通常还是个优先队列。kube-scheduler也不例外。
看看scheduler的结构:
// 文件路径:pkg/scheduler/scheduler.go
// Scheduler watches for new unscheduled pods. It attempts to find
// nodes that they fit on and writes bindings back to the api server.
type Scheduler struct {
// It is expected that changes made via SchedulerCache will be observed
// by NodeLister and Algorithm.
SchedulerCache internalcache.Cache
Algorithm core.ScheduleAlgorithm
// NextPod should be a function that blocks until the next pod
// is available. We don't use a channel for this, because scheduling
// a pod may take some amount of time and we don't want pods to get
// stale while they sit in a channel.
NextPod func() *framework.QueuedPodInfo
// Error is called if there is an error. It is passed the pod in
// question, and the error
Error func(*framework.QueuedPodInfo, error)
// Close this to shut down the scheduler.
StopEverything <-chan struct{}
// SchedulingQueue holds pods to be scheduled
SchedulingQueue internalqueue.SchedulingQueue
// Profiles are the scheduling profiles.
Profiles profile.Map
client clientset.Interface
}内容不多,里面有一个调度队列,队列的接口和具体结构如下:
// 文件路径: pkg/scheduler/internal/queue/scheduling_queue.go
// SchedulingQueue定义了一个队列接口,用于保存等待调度的pod信息,
type SchedulingQueue interface {
framework.PodNominator
Add(pod *v1.Pod) error
// AddUnschedulableIfNotPresent adds an unschedulable pod back to scheduling queue.
// The podSchedulingCycle represents the current scheduling cycle number which can be
// returned by calling SchedulingCycle().
AddUnschedulableIfNotPresent(pod *framework.QueuedPodInfo, podSchedulingCycle int64) error
// SchedulingCycle returns the current number of scheduling cycle which is
// cached by scheduling queue. Normally, incrementing this number whenever
// a pod is popped (e.g. called Pop()) is enough.
SchedulingCycle() int64
// Pop removes the head of the queue and returns it. It blocks if the
// queue is empty and waits until a new item is added to the queue.
Pop() (*framework.QueuedPodInfo, error)
Update(oldPod, newPod *v1.Pod) error
Delete(pod *v1.Pod) error
MoveAllToActiveOrBackoffQueue(event string)
AssignedPodAdded(pod *v1.Pod)
AssignedPodUpdated(pod *v1.Pod)
PendingPods() []*v1.Pod
// Close closes the SchedulingQueue so that the goroutine which is
// waiting to pop items can exit gracefully.
Close()
// NumUnschedulablePods returns the number of unschedulable pods exist in the SchedulingQueue.
NumUnschedulablePods() int
// Run starts the goroutines managing the queue.
Run()
}
// Pod提名信息的控制接口
type PodNominator interface {
// AddNominatedPod adds the given pod to the nominated pod map or
// updates it if it already exists.
AddNominatedPod(pod *v1.Pod, nodeName string)
// DeleteNominatedPodIfExists deletes nominatedPod from internal cache. It's a no-op if it doesn't exist.
DeleteNominatedPodIfExists(pod *v1.Pod)
// UpdateNominatedPod updates the <oldPod> with <newPod>.
UpdateNominatedPod(oldPod, newPod *v1.Pod)
// NominatedPodsForNode returns nominatedPods on the given node.
NominatedPodsForNode(nodeName string) []*v1.Pod
}
// PriorityQueue是具体的实现
// 队列的头是等待调度的pod里优先级最高的
// 包括三个子队列
type PriorityQueue struct {
// 存储、设置调度的提名信息,其实就是调度的结果:pod和node的对应关系
framework.PodNominator
// 外部控制队列的channel
stop chan struct{}
clock util.Clock
// backoff pod 初始的等待重新调度时间
podInitialBackoffDuration time.Duration
// backoff pod 最大的等待重新调度的时间
podMaxBackoffDuration time.Duration
lock sync.RWMutex
// 并发场景下,控制pop的阻塞
cond sync.Cond
// 阻塞队列
activeQ *heap.Heap
// backoff队列
podBackoffQ *heap.Heap
// 不可调度队列
unschedulableQ *UnschedulablePodsMap
// 一个计数器,每次pop一个pod,自增一次
schedulingCycle int64
// moveRequestCycle caches the sequence number of scheduling cycle when we
// received a move request. Unscheduable pods in and before this scheduling
// cycle will be put back to activeQueue if we were trying to schedule them
// when we received move request.
moveRequestCycle int64
// 控制队列的开关
closed bool
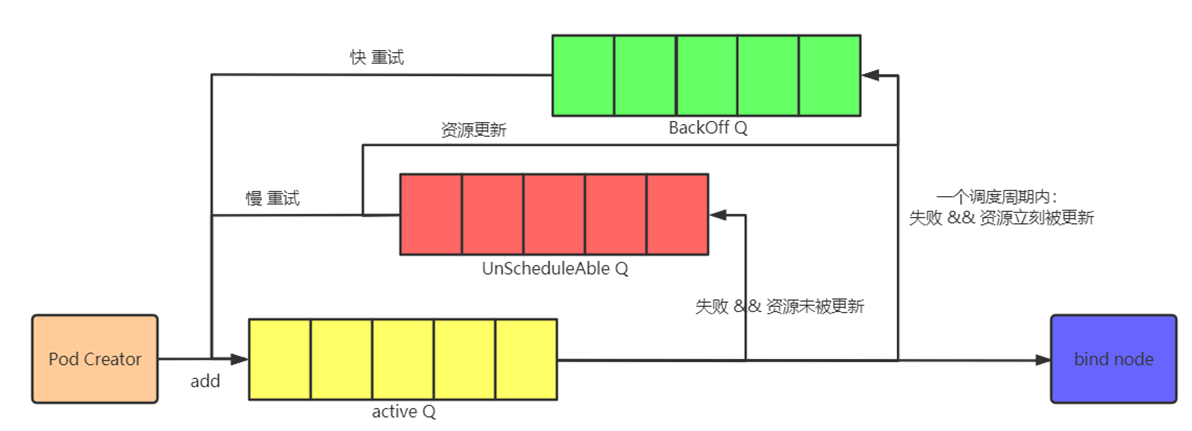
}PriorityQueue作为实现SchedulingQueue的实现,其核心数据结构主要包含三个队列:activeQ、podBackoffQ、unscheduleQ。
内部通过cond来实现Pop操作的阻塞与通知,接下来先分析核心的调度流程。util.heap结构就是堆结构,这里自行想象其实现即可。
3.2.1 activeQ
存储所有等待调度的Pod的队列,默认是基于堆来实现,其中元素的优先级则通过对比pod的创建时间和pod的优先级来进行排序。
既然是堆,那么必然需要定义一下堆结构的元素优先级比较方法;这块代码定义在framework路径下:
// 文件路径: pkg/scheduler/framework/plugins/queuesort/priority_sort.go
// PrioritySort is a plugin that implements Priority based sorting.
type PrioritySort struct{}
// Less 是activeQ默认的排序方法
// 该方法根据pod的优先级来排序,如果优先级一样,则根据pod的timestamp来决定优先级
func (pl *PrioritySort) Less(pInfo1, pInfo2 *framework.QueuedPodInfo) bool {
p1 := pod.GetPodPriority(pInfo1.Pod)
p2 := pod.GetPodPriority(pInfo2.Pod)
return (p1 > p2) || (p1 == p2 && pInfo1.Timestamp.Before(pInfo2.Timestamp))
}这里的GetPodPriority方法做了啥呢?
我们进一步往下看:
// 文件路径:pkg/api/v1/pod/util.go
// 从pod的配置种获取优先等级的设置,没有则返回0
func GetPodPriority(pod *v1.Pod) int32 {
if pod.Spec.Priority != nil {
return *pod.Spec.Priority
}
return 0
}这里的实现和我们实际的功能表现对上了,priorityclass字段控制着pod调度的优先级,优先级高的pod,会被直接排到最前面。
3.2.2 podbackoffQ
熟悉k8s的人会注意到,一般执行失败的pod,会有一些backoff的event,这个backoff是什么意思呢?
backoff机制是并发编程中常见的一种机制,即如果任务反复执行依旧失败,则会按次增长等待调度时间,降低重试效率,从而避免反复失败浪费调度资源。
针对调度失败的pod会优先存储在backoff队列中,等待后续重试。
podBackOffQ主要存储那些在多个schedulingCycle中依旧调度失败的情况下,则会通过之前说的backOff机制,延迟等待调度的时间。
backoffQ也是一个优先队列,那么它的默认比较方法如下所示,简单粗暴,根据失败的时间来排序:
// 文件路径: pkg/scheduler/internal/queue/scheduling_queue.go
func (p *PriorityQueue) podsCompareBackoffCompleted(podInfo1, podInfo2 interface{}) bool {
pInfo1 := podInfo1.(*framework.QueuedPodInfo)
pInfo2 := podInfo2.(*framework.QueuedPodInfo)
bo1 := p.getBackoffTime(pInfo1)
bo2 := p.getBackoffTime(pInfo2)
return bo1.Before(bo2)
}
// getBackoffTime returns the time that podInfo completes backoff
func (p *PriorityQueue) getBackoffTime(podInfo *framework.QueuedPodInfo) time.Time {
duration := p.calculateBackoffDuration(podInfo)
backoffTime := podInfo.Timestamp.Add(duration)
return backoffTime
}
// 计算backoff时间
func (p *PriorityQueue) calculateBackoffDuration(podInfo *framework.QueuedPodInfo) time.Duration {
duration := p.podInitialBackoffDuration
for i := 1; i < podInfo.Attempts; i++ {
duration = duration * 2
if duration > p.podMaxBackoffDuration {
return p.podMaxBackoffDuration
}
}
return duration
}3.2.4 unschedulableQ
字面意思,不可调度队列。
虽说是个队列,实际的数据结构是一个map。
// 文件路径: pkg/scheduler/internal/queue/scheduling_queue.go
// 存储暂时无法被调度的pod信息
// 例如: 资源不足,无法被调度
type UnschedulablePodsMap struct {
// podInfoMap 是一个map,他的key是pod的full-name,值是指向pod信息的指针,想不到吧 go里面也有指针,相当于引用
podInfoMap map[string]*framework.QueuedPodInfo
keyFunc func(*v1.Pod) string
// 注释很浅显,字面意思
// metricRecorder updates the counter when elements of an unschedulablePodsMap
// get added or removed, and it does nothing if it's nil
metricRecorder metrics.MetricRecorder
}
// 不可调度队列的构造函数,看得出来,keyfunc里获取pod的全名
func newUnschedulablePodsMap(metricRecorder metrics.MetricRecorder) *UnschedulablePodsMap {
return &UnschedulablePodsMap{
podInfoMap: make(map[string]*framework.QueuedPodInfo),
keyFunc: util.GetPodFullName,
metricRecorder: metricRecorder,
}
3.2.4 Scheduler.RUN
这三级队列,怎么用的呢?
// 文件路径:pkg/scheduler/scheduler.go
// scheduler的RUN方法
func (sched *Scheduler) Run(ctx context.Context) {
sched.SchedulingQueue.Run()
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
sched.SchedulingQueue.Close()
}// 文件路径: pkg/scheduler/internal/queue/scheduling_queue.go
// PriorityQueue的RUN方法
func (p *PriorityQueue) Run() {
go wait.Until(p.flushBackoffQCompleted, 1.0*time.Second, p.stop)
go wait.Until(p.flushUnschedulableQLeftover, 30*time.Second, p.stop)
}
// 文件路径 pkg/scheduler/scheduler.go
// scheduleOne方法是调度的核心方法,该方法里,为一个pod的调度走了完整的调度流程
func (sched *Scheduler) scheduleOne(ctx context.Context) {
// 方法太长,后面再详细分析
}
很明显,调度器是这样工作的:
有三条工作流在同时运行:
- 每隔1秒,检测backoffQ里是否有pod可以被放进activeQ里
- 每隔30秒,检测unschedulepodQ里是否有pod可以被放进activeQ里(默认条件是等待时间超过60秒)
- 不停的调用scheduleOne方法,从activeQ里取出pod来进行调度
3.2.5 失败与重试处理
看完上面的分析,应该还有一个问题没有解决,既然有两个失败的队列:
- backoffQ
- unScheduleQ
那么什么情况下要放进backoff里,什么情况下,进unschedule呢?进去unschedule后,只能等时间到了才重新拿出来调度吗?
这里我们就要提一下优先队列里,还有两个重要的值属性了:
- schedulingCycle
- moveRequestCycle
以及几个对外暴露的方法:
- AddUnschedulableIfNotPresent
- AssignedPodAdded
- AssignedPodUpdated
- MoveAllToActiveOrBackoffQueue
我们设想一下,当前如果有一个pod调度失败了,只有一个可能,就是当前没有能满足它要求的资源。换言之,它属于unScheduleable,不可调度的。
如果集群内的状态一直不发生变化,理论上它会一直处于不可调度的状态,根据前面RUN方法里的定时器,这种情况下,每隔60秒,这些pod还是会被重新尝试调度一次。
但是一旦集群的状态发生了变化,很有可能,这些不可调度的pod,就能获取自己想要的资源了,换言之,集群状态变化后,unscheduleableQ的pod应该放进backoffQ里。等待安排重新调度。backoffQ里的pod会根据重试的次数设定等待重试的时间,重试的次数越少,等待重新调度的时间也就越少。换言之,backOffQ里的pod调度的速度会比unscheduleableQ里的pod快得多,肯定不需要等60秒那么久。
如果还记得上次分享的client-go的内容的话,应该记得k8s的client会提供informer机制,用于在本地同步集群上的资源状态,在scheduler种,需要监控pod、pv、node等多种资源,这些都是借助shared_informer机制来实现的。
而AssignedPodAdded、AssignedPodUpdated、MoveAllToActiveOrBackoffQueue主要被用来设置资源更新时的回调方法。也就是在新的pod被创建、更新,或者别的资源更新时,k8s会认为之前无法被调度的pod,有了重试的机会。这三个方法在底层都会调用movePodsToActiveOrBackoffQueue方法:
// 文件路径: pkg/scheduler/internal/queue/scheduling_queue.go
// NOTE: this function assumes lock has been acquired in caller
func (p *PriorityQueue) movePodsToActiveOrBackoffQueue(podInfoList []*framework.QueuedPodInfo, event string) {
for _, pInfo := range podInfoList {
pod := pInfo.Pod
if p.isPodBackingoff(pInfo) {
if err := p.podBackoffQ.Add(pInfo); err != nil {
klog.Errorf("Error adding pod %v to the backoff queue: %v", pod.Name, err)
} else {
metrics.SchedulerQueueIncomingPods.WithLabelValues("backoff", event).Inc()
p.unschedulableQ.delete(pod)
}
} else {
if err := p.activeQ.Add(pInfo); err != nil {
klog.Errorf("Error adding pod %v to the scheduling queue: %v", pod.Name, err)
} else {
metrics.SchedulerQueueIncomingPods.WithLabelValues("active", event).Inc()
p.unschedulableQ.delete(pod)
}
}
}
p.moveRequestCycle = p.schedulingCycle
p.cond.Broadcast()
}看完这块逻辑,可以知道,资源更新后,不可调度的pod会被重新放进activeQ或者backoffQ。同时,moveRequestCycle会设置为当前的schedulingCycle。
最后看看AddUnschedulableIfNotPresent方法,以及这个方法被使用的场景:
// 文件路径: pkg/scheduler/internal/queue/scheduling_queue.go
func (p *PriorityQueue) AddUnschedulableIfNotPresent(pInfo *framework.QueuedPodInfo, podSchedulingCycle int64) error {
p.lock.Lock()
defer p.lock.Unlock()
pod := pInfo.Pod
if p.unschedulableQ.get(pod) != nil {
return fmt.Errorf("pod: %v is already present in unschedulable queue", nsNameForPod(pod))
}
// Refresh the timestamp since the pod is re-added.
pInfo.Timestamp = p.clock.Now()
if _, exists, _ := p.activeQ.Get(pInfo); exists {
return fmt.Errorf("pod: %v is already present in the active queue", nsNameForPod(pod))
}
if _, exists, _ := p.podBackoffQ.Get(pInfo); exists {
return fmt.Errorf("pod %v is already present in the backoff queue", nsNameForPod(pod))
}
// If a move request has been received, move it to the BackoffQ, otherwise move
// it to unschedulableQ.
if p.moveRequestCycle >= podSchedulingCycle {
if err := p.podBackoffQ.Add(pInfo); err != nil {
return fmt.Errorf("error adding pod %v to the backoff queue: %v", pod.Name, err)
}
metrics.SchedulerQueueIncomingPods.WithLabelValues("backoff", ScheduleAttemptFailure).Inc()
} else {
p.unschedulableQ.addOrUpdate(pInfo)
metrics.SchedulerQueueIncomingPods.WithLabelValues("unschedulable", ScheduleAttemptFailure).Inc()
}
p.PodNominator.AddNominatedPod(pod, "")
return nil
}
// 文件路径: pkg/scheduler/factory.go
func MakeDefaultErrorFunc(client clientset.Interface, podLister corelisters.PodLister, podQueue internalqueue.SchedulingQueue, schedulerCache internalcache.Cache) func(*framework.QueuedPodInfo, error) {
return func(podInfo *framework.QueuedPodInfo, err error) {
pod := podInfo.Pod
if err == core.ErrNoNodesAvailable {
klog.V(2).InfoS("Unable to schedule pod; no nodes are registered to the cluster; waiting", "pod", klog.KObj(pod))
} else if _, ok := err.(*core.FitError); ok {
klog.V(2).InfoS("Unable to schedule pod; no fit; waiting", "pod", klog.KObj(pod), "err", err)
} else if apierrors.IsNotFound(err) {
klog.V(2).Infof("Unable to schedule %v/%v: possibly due to node not found: %v; waiting", pod.Namespace, pod.Name, err)
if errStatus, ok := err.(apierrors.APIStatus); ok && errStatus.Status().Details.Kind == "node" {
nodeName := errStatus.Status().Details.Name
// when node is not found, We do not remove the node right away. Trying again to get
// the node and if the node is still not found, then remove it from the scheduler cache.
_, err := client.CoreV1().Nodes().Get(context.TODO(), nodeName, metav1.GetOptions{})
if err != nil && apierrors.IsNotFound(err) {
node := v1.Node{ObjectMeta: metav1.ObjectMeta{Name: nodeName}}
if err := schedulerCache.RemoveNode(&node); err != nil {
klog.V(4).Infof("Node %q is not found; failed to remove it from the cache.", node.Name)
}
}
}
} else {
klog.ErrorS(err, "Error scheduling pod; retrying", "pod", klog.KObj(pod))
}
// Check if the Pod exists in informer cache.
cachedPod, err := podLister.Pods(pod.Namespace).Get(pod.Name)
if err != nil {
klog.Warningf("Pod %v/%v doesn't exist in informer cache: %v", pod.Namespace, pod.Name, err)
return
}
// As <cachedPod> is from SharedInformer, we need to do a DeepCopy() here.
podInfo.Pod = cachedPod.DeepCopy()
if err := podQueue.AddUnschedulableIfNotPresent(podInfo, podQueue.SchedulingCycle()); err != nil {
klog.Error(err)
}
}
}
MakeDefaultErrorFunc方法会在构建调度器实例时被传入,作为默认的错误处理方法,在pod调度失败时,默认执行此方法,在此方法里,会调用AddUnschedulableIfNotPresent,会有一个判断:
- 如果moveRequestCycle大于等于当前的podSchedulingCycle,则当前应该对之前已经失败的pod进行重试,也就是放进backoffQ里
- 如果不满足,则放进unscheduleableQ里
结合moveRequestCycle的变更机制,可以知道,只有集群资源发生过变更,moveRequestCycle才会等于podSchedulingCycle。结合起来,可以理解一下这里错误处理的细节。在pod调度失败时,正常情况下,会被放进unscheduleableQ队列,但是在某些情况下,pod刚刚调度失败,在错误处理之前,忽然发生了资源变更,紧接着再调用错误处理回调,这个时候,由于在这个错误处理的间隙,集群的状态已经发生了变化,所以可以认为这个pod应该有了被调度成功的可能性,所以就被放进了backoffQ重试队列种,等待快速重试。
这样的一种资源更新回调、错误处理机制,本质上就是为了尽可能快的把调度失败的pod重新调取起来,缩短等待调度的时间。
最终队列的工作方式如下:
3.3 调度器实例
3.3.1 调度器的构造
调度器的代码比较复杂,我们需要找一个切入点。找到最外层调度器的类型定义,在文件pkg/scheduler/scheduler.go中,
// 文件路径 pkg/scheduler/scheduler.go
// Scheduler
type Scheduler struct {
SchedulerCache internalcache.Cache
Algorithm core.ScheduleAlgorithm
// NextPod获取下一个待调度的pod
NextPod func() *framework.QueuedPodInfo
// Error是默认的调度失败处理方法
Error func(*framework.QueuedPodInfo, error)
// Close this to shut down the scheduler.
StopEverything <-chan struct{}
// 上面提到的三级队列
SchedulingQueue internalqueue.SchedulingQueue
// 调度配置 很重要,控制整个调度过程的核心
Profiles profile.Map
client clientset.Interface
}我们看下它的工厂方法,关键步骤,我给加上了注释
// 文件路径 pkg/scheduler/scheduler.go
// New returns a Scheduler
func New(client clientset.Interface,
informerFactory informers.SharedInformerFactory,
recorderFactory profile.RecorderFactory,
stopCh <-chan struct{},
opts ...Option) (*Scheduler, error) {
stopEverything := stopCh
if stopEverything == nil {
stopEverything = wait.NeverStop
}
// 获取默认的调度器选项
// 1. 里面会设定一些默认的组件参数
// 2. 里面会给定默认的algorithmSourceProvider,这个很关键,后续的调度全部依赖这里提供的算法
options := defaultSchedulerOptions
for _, opt := range opts {
opt(&options)
}
// 初始化调度缓存
schedulerCache := internalcache.New(30*time.Second, stopEverything)
// registry是一个字典,里面存放了插件名与插件的工厂方法
// 默认有接近30个插件
registry := frameworkplugins.NewInTreeRegistry()
if err := registry.Merge(options.frameworkOutOfTreeRegistry); err != nil {
return nil, err
}
snapshot := internalcache.NewEmptySnapshot()
// 基于配置 创建configurator实例
configurator := &Configurator{
client: client,
recorderFactory: recorderFactory,
informerFactory: informerFactory,
schedulerCache: schedulerCache,
StopEverything: stopEverything,
percentageOfNodesToScore: options.percentageOfNodesToScore,
podInitialBackoffSeconds: options.podInitialBackoffSeconds,
podMaxBackoffSeconds: options.podMaxBackoffSeconds,
profiles: append([]schedulerapi.KubeSchedulerProfile(nil), options.profiles...),
registry: registry,
nodeInfoSnapshot: snapshot,
extenders: options.extenders,
frameworkCapturer: options.frameworkCapturer,
}
metrics.Register()
var sched *Scheduler
source := options.schedulerAlgorithmSource
switch {
// 这里Provider默认不为空,会走这个分支
case source.Provider != nil:
// Create the config from a named algorithm provider.
sc, err := configurator.createFromProvider(*source.Provider)
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler using provider %q: %v", *source.Provider, err)
}
sched = sc
case source.Policy != nil:
// Create the config from a user specified policy source.
policy := &schedulerapi.Policy{}
switch {
case source.Policy.File != nil:
if err := initPolicyFromFile(source.Policy.File.Path, policy); err != nil {
return nil, err
}
case source.Policy.ConfigMap != nil:
if err := initPolicyFromConfigMap(client, source.Policy.ConfigMap, policy); err != nil {
return nil, err
}
}
configurator.extenders = policy.Extenders
sc, err := configurator.createFromConfig(*policy)
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler from policy: %v", err)
}
sched = sc
default:
return nil, fmt.Errorf("unsupported algorithm source: %v", source)
}
// Additional tweaks to the config produced by the configurator.
sched.StopEverything = stopEverything
sched.client = client
// 这一步启动所有的事件监听
addAllEventHandlers(sched, informerFactory)
return sched, nil
}上述的初始化过程中,有两个步骤可以特别关注下,一个是默认的algorithmSourceProvider,一个是addAllEventHandlers,我们拎出来看一下:
// 文件路径 pkg/scheduler/algorithmprovider/registry.go
// 默认的调度算法配置就是由该方法提供的
// 可以看到,各个阶段的名字以及对应的算法名;
// 部分插件还设置了权重,以供计算后进一步的筛选使用
func getDefaultConfig() *schedulerapi.Plugins {
return &schedulerapi.Plugins{
QueueSort: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: queuesort.Name},
},
},
PreFilter: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: noderesources.FitName},
{Name: nodeports.Name},
{Name: podtopologyspread.Name},
{Name: interpodaffinity.Name},
{Name: volumebinding.Name},
},
},
Filter: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: nodeunschedulable.Name},
{Name: noderesources.FitName},
{Name: nodename.Name},
{Name: nodeports.Name},
{Name: nodeaffinity.Name},
{Name: volumerestrictions.Name},
{Name: tainttoleration.Name},
{Name: nodevolumelimits.EBSName},
{Name: nodevolumelimits.GCEPDName},
{Name: nodevolumelimits.CSIName},
{Name: nodevolumelimits.AzureDiskName},
{Name: volumebinding.Name},
{Name: volumezone.Name},
{Name: podtopologyspread.Name},
{Name: interpodaffinity.Name},
},
},
PostFilter: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: defaultpreemption.Name},
},
},
PreScore: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: interpodaffinity.Name},
{Name: podtopologyspread.Name},
{Name: tainttoleration.Name},
},
},
Score: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: noderesources.BalancedAllocationName, Weight: 1},
{Name: imagelocality.Name, Weight: 1},
{Name: interpodaffinity.Name, Weight: 1},
{Name: noderesources.LeastAllocatedName, Weight: 1},
{Name: nodeaffinity.Name, Weight: 1},
{Name: nodepreferavoidpods.Name, Weight: 10000},
// Weight is doubled because:
// - This is a score coming from user preference.
// - It makes its signal comparable to NodeResourcesLeastAllocated.
{Name: podtopologyspread.Name, Weight: 2},
{Name: tainttoleration.Name, Weight: 1},
},
},
Reserve: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: volumebinding.Name},
},
},
PreBind: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: volumebinding.Name},
},
},
Bind: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: defaultbinder.Name},
},
},
}
}
// 文件路径 pkg/scheduler/eventhandlers.go
// addAllEventHandlers
// 其实就是加回调,省略了部分代码
func addAllEventHandlers(
sched *Scheduler,
informerFactory informers.SharedInformerFactory,
) {
informerFactory.Core().V1().Pods().Informer().AddEventHandler(
...
)
informerFactory.Core().V1().Pods().Informer().AddEventHandler(
...
)
informerFactory.Core().V1().Nodes().Informer().AddEventHandler(
...
)
if utilfeature.DefaultFeatureGate.Enabled(features.CSINodeInfo) {
informerFactory.Storage().V1().CSINodes().Informer().AddEventHandler(
...
)
}
informerFactory.Core().V1().PersistentVolumes().Informer().AddEventHandler(
...
)
informerFactory.Core().V1().PersistentVolumeClaims().Informer().AddEventHandler(
...
)
informerFactory.Core().V1().Services().Informer().AddEventHandler(
...
)
informerFactory.Storage().V1().StorageClasses().Informer().AddEventHandler(
...
)
}
addAllEventHandlers方法里把client-go的内容和调度队列的内容衔接起来了,调度器通过这些给这些资源加回调方法更新本地状态同时更新调度队列里的unscheduleableQ。
3.3.2 调度器的运行
看完了调度器的构造,之后就是调度器的启动。前面也提到:
// 文件路径:pkg/scheduler/scheduler.go
// scheduler的RUN方法
func (sched *Scheduler) Run(ctx context.Context) {
sched.SchedulingQueue.Run()
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
sched.SchedulingQueue.Close()
}调度队列已经分析过,我们这里只需要看scheduleOne这个方法。
具体过程如下:
1. 选择pod对应的调度算法,pod配置里会指定调度器的名字,默认是defaultscheduler,如果指定的调度器名字不存在,则会报错,停止调度
prof, err := sched.profileForPod(pod)
2. 检测是否需要跳过调度,这里会检测pod是否已经被调度或者被指定了node
if sched.skipPodSchedule(prof, pod) {
return
}
3. 调用prof的算法进行调度,这里的prof其实就是第一步里,根据pod配置,获取到的调度配置,具体这里怎么调度的,我们后面再看
scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, prof, state, pod)
4. 如果第三步的调度失败,则会判断prof内,是否存在postfilter阶段的插件,如果有则运行。还记得前面提到的默认的algorimpSourceProvider的配置么,默认的postfilter的插件名字叫DefaultPreemption。没错,就是执行抢占任务的。具体怎么抢占的,后面再看。这里继续。
result, status := prof.RunPostFilterPlugins(ctx, state, pod, fitError.FilteredNodesStatuses)
5. 如果成功调度到了一个节点,先更改调度器本地缓存里的数据,然后另起一个协程执行pod与node的绑定操作。这样可以无需等待绑定的结果,立刻开启下一个pod的调度。
assumedPodInfo := podInfo.DeepCopy()
assumedPod := assumedPodInfo.Pod
err = sched.assume(assumedPod, scheduleResult.SuggestedHost)
...
go func() {
prebind..
bind..
postbind..
}大致的调度流程就是这样,这里面,有两个关键步骤,一个是下一层的调度逻辑,一个是抢占逻辑。
3.3.3 预选与优选
// 文件路径 pkg/scheduler/core/generic_scheduler.go
// 最最最核心的调度逻辑
func (g *genericScheduler) Schedule(ctx context.Context, prof *profile.Profile, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
if g.nodeInfoSnapshot.NumNodes() == 0 {
return result, ErrNoNodesAvailable
}
startPredicateEvalTime := time.Now()
// 预选,找到一些符合基本条件的node
feasibleNodes, filteredNodesStatuses, err := g.findNodesThatFitPod(ctx, prof, state, pod)
if err != nil {
return result, err
}
...
startPriorityEvalTime := time.Now()
// 如果预选阶段只留下了一个node,直接用
if len(feasibleNodes) == 1 {
return ScheduleResult{
SuggestedHost: feasibleNodes[0].Name,
EvaluatedNodes: 1 + len(filteredNodesStatuses),
FeasibleNodes: 1,
}, nil
}
// 如果不止一个node,那么再进行优选,优选阶段会给每个node打分,选择分数最高的作为最终的调度结果
priorityList, err := g.prioritizeNodes(ctx, prof, state, pod, feasibleNodes)
if err != nil {
return result, err
}
host, err := g.selectHost(priorityList)
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(feasibleNodes) + len(filteredNodesStatuses),
FeasibleNodes: len(feasibleNodes),
}, err
}预选阶段的处理:
- 运行所有的prefilter插件
- 运行所有的filter插件
- 如果存在extender,执行extender的filter方法
还是之前提到的,默认的prefilter\filter信息如下,大概知道就行了,具体规则看不过来就略过了。
PreFilter: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: noderesources.FitName},
{Name: nodeports.Name},
{Name: podtopologyspread.Name},
{Name: interpodaffinity.Name},
{Name: volumebinding.Name},
},
},
Filter: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: nodeunschedulable.Name},
{Name: noderesources.FitName},
{Name: nodename.Name},
{Name: nodeports.Name},
{Name: nodeaffinity.Name},
{Name: volumerestrictions.Name},
{Name: tainttoleration.Name},
{Name: nodevolumelimits.EBSName},
{Name: nodevolumelimits.GCEPDName},
{Name: nodevolumelimits.CSIName},
{Name: nodevolumelimits.AzureDiskName},
{Name: volumebinding.Name},
{Name: volumezone.Name},
{Name: podtopologyspread.Name},
{Name: interpodaffinity.Name},
},
},extender是调度的一种外部扩展机制,这种机制实际已经慢慢在被淘汰,默认是没有extender的。
优选阶段做的事情,就是把所有prescore和score的插件跑了一遍,给每个node打分。
仔细看看挺有意思的,这个阶段会考虑很多因素,比如亲和性、资源富裕度,甚至镜像的本地性。
PreScore: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: interpodaffinity.Name},
{Name: podtopologyspread.Name},
{Name: tainttoleration.Name},
},
},
Score: &schedulerapi.PluginSet{
Enabled: []schedulerapi.Plugin{
{Name: noderesources.BalancedAllocationName, Weight: 1},
{Name: imagelocality.Name, Weight: 1},
{Name: interpodaffinity.Name, Weight: 1},
{Name: noderesources.LeastAllocatedName, Weight: 1},
{Name: nodeaffinity.Name, Weight: 1},
{Name: nodepreferavoidpods.Name, Weight: 10000},
// Weight is doubled because:
// - This is a score coming from user preference.
// - It makes its signal comparable to NodeResourcesLeastAllocated.
{Name: podtopologyspread.Name, Weight: 2},
{Name: tainttoleration.Name, Weight: 1},
},
},3.3.4 抢占
具体逻辑在文件pkg/scheduler/framework/plugins/defaultpreemption/default_preemption.go中,暂时预留此节,之后详细分析。
3.4 调度框架的扩展设计
3.4.1 外部扩展机制:SchedulerExtender
SchdulerExtender是k8s外部扩展方式,用户可以根据需求独立构建调度服务,实现对应的远程调用接口(目前是http), scheduler在调度的对应阶段会根据用户定义的资源和接口来进行远程调用,对应的service根据自己的资源数据和scheduler传递过来的中间调度结果来进行决策。
因为是独立的服务,extender可以实现自定义资源的存储与获取,甚至可以不依赖于etcd使用第三方的存储来进行资源的存储,主要是用于kubernetes中不支持的那些资源的调度扩展.
3.4.1 内部扩展机制:Framework
Framework是kubernetes扩展的第二种实现,相比SchedulerExtender基于远程独立Service的扩展,Framework核心则实现了一种基于扩展点的本地化的规范流程管理机制。
目前官方主要是围绕着之前的预选和优选阶段进行扩展,提供了更多的扩展点,其中每个扩展点都是一类插件,我们可以根据我们的需要在对应的阶段来进行扩展插件的编写,实现调度增强。
在当前版本中优先级插件已经抽取到了framework中,后续应该会继续将预选插件来进行抽取,这块应该还得一段时间才能稳定。
发表回复
要发表评论,您必须先登录。