Contents
对于业务开发人员而言,底层网络是一个不可见的黑盒,所以相对也有一些陌生。
我们要理解容器网络的知识,需要从理解计算机网络、普通的主机网络通信开始。
1. 网络基础概念
网络的事情,说来话长。
作为背景内容,我们简单回顾一下计算机网络协议。
众所周知,OSI的分层模型中,分为7层。依次为:
- 物理层
- 数据链路层
- 网络层
- 传输层
- 会话层
- 表示层
- 应用层
物理层,包含一些走线、集线器、中继器、网卡设备。
数据链路层,主要包含逻辑链路控制(Logical Link Control)、介质控制(MAC, Media Access Control)相关的一些设备,负责网络寻址、错帧检测等功能。网络上的所有数据其实也是在这一层进行传输。这一层是我们常说的二层。
三层是网络层,负责数据传输的路径选择和转寄。这一层的协议主要是IP, Internet Protocol协议。IP协议定义了我们经常使用的IP地址等信息,我们最终也依赖IP地址,进行路径选择。
四层就是传输层,这一层主要涉及的协议有TCP, Transport Control Protocol 以及UDP, User Data Protocol。
会话层、表示层、应用层,这三层有时候会被统称为应用层,主要是一些更接网络使用者的一些协议,比如HTTP、HTTPS、POP3等。
我们该如何理解网络分层呢?
我画了一个图帮助理解:
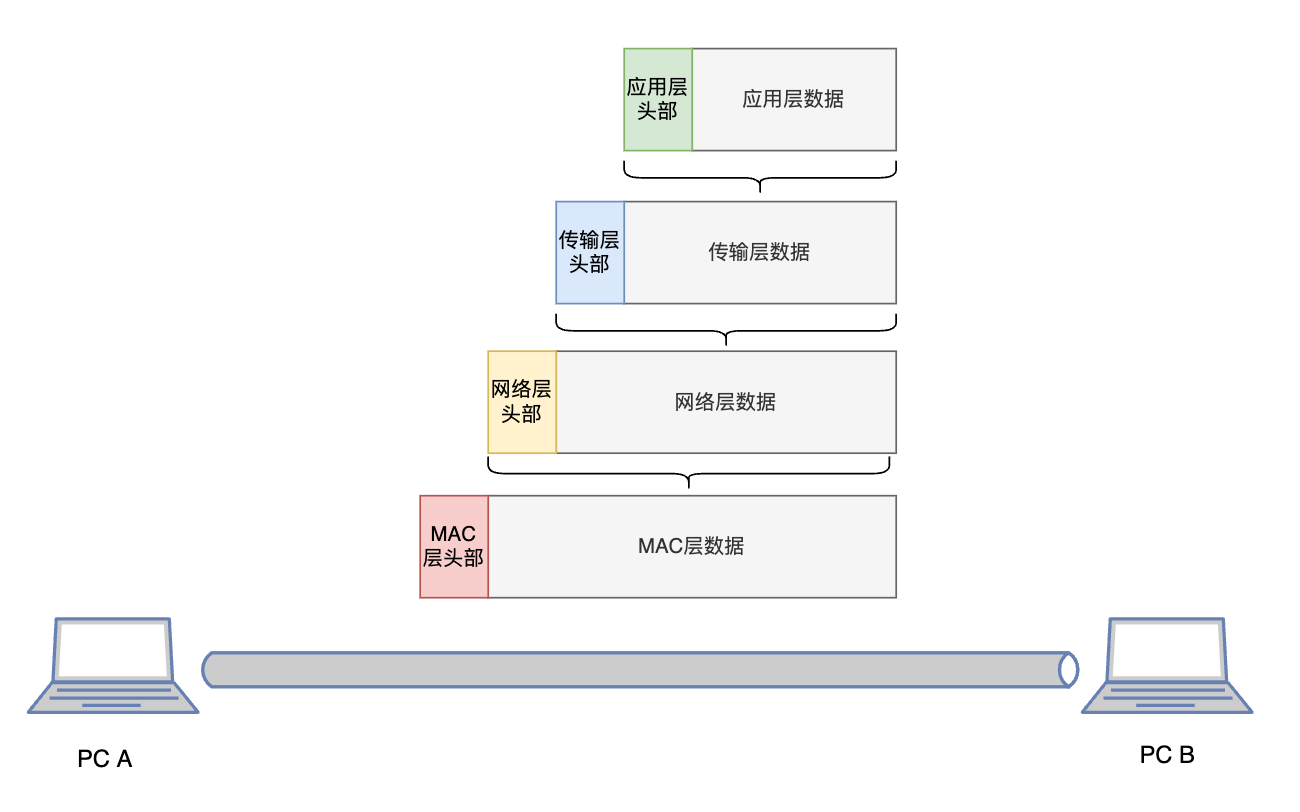
解释起来就是
- 上层协议的完整数据,是下一层协议的负载;
- 每一层协议会进行封装和解封装的步骤,也就是拆包和装包,装包是为本层数据加上本层协议自己的头部(header),用于带上一些标记信息和控制字段;拆包,则是解析出头部字段,并取出本层的负载数据,交由网络协议栈进一步的处理。
假设PC A和PC B的正在进行HTTP的通信,那么A接受的每一个数据帧,都携带了完整的HTTP、TCP、IP、MAC四层协议信息与头部,经过网络协议栈的层层解析,最终获取到用户想要传递的数据。
1.1 二层与三层网络简述
我们从最基本的场景开始谈起,一步步理解目前复杂的网络寻址过程。
1.1.1 两个PC进行网络互联

假设网络中,只有两台机器,那么我们可以通过一根网线,连接这两个机器,完成网络的搭建。
1.1.2 PC的数量开始增加–集线器与交换机
随着网络终端的增加,这样的网络模型变的复杂:
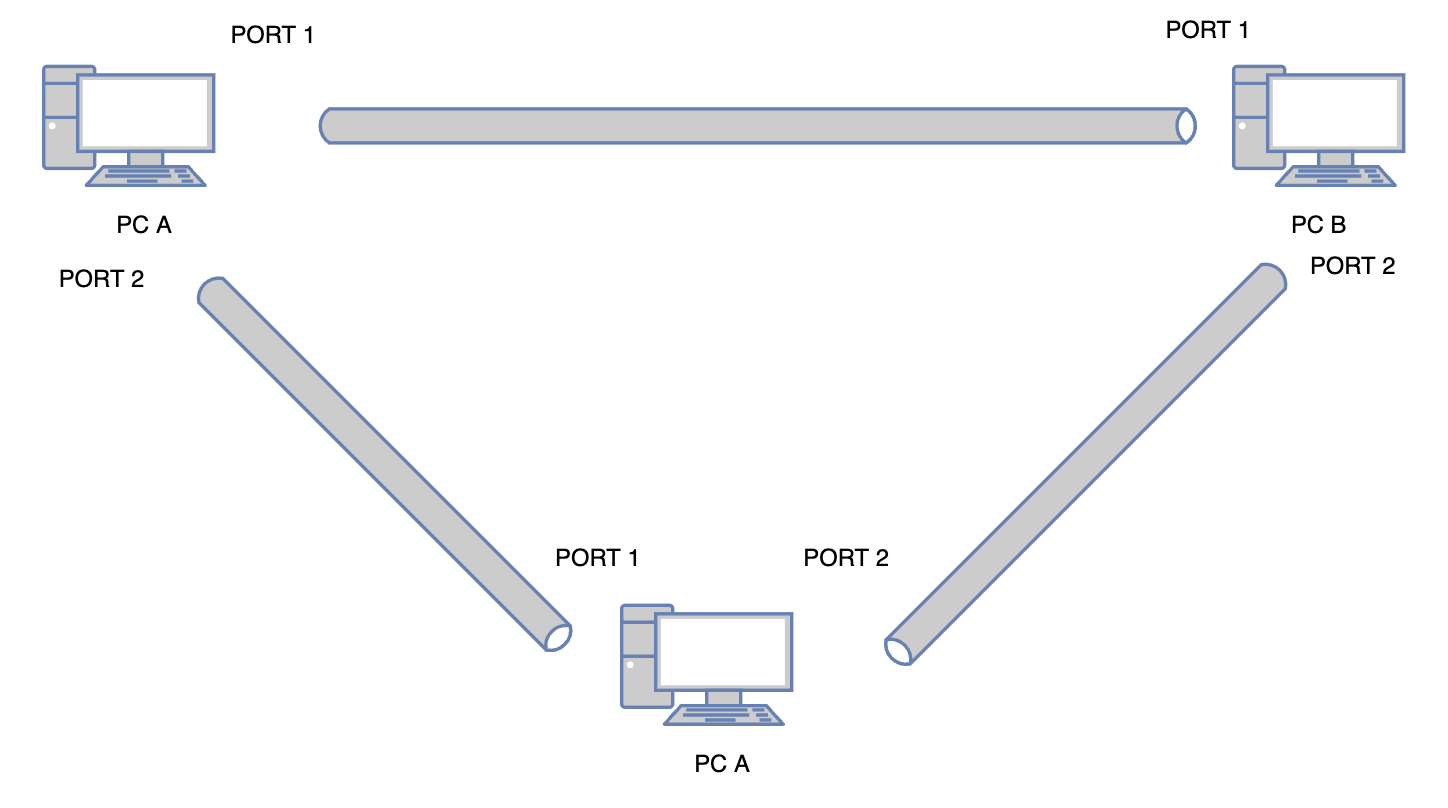
如果继续这样加终端设备,我们很快会遇到两个问题:
- 走线过于复杂
- 占用过多端口
解决方案就是,采用消息总线+消息的碰撞检测算法,进行消息的传输和分流
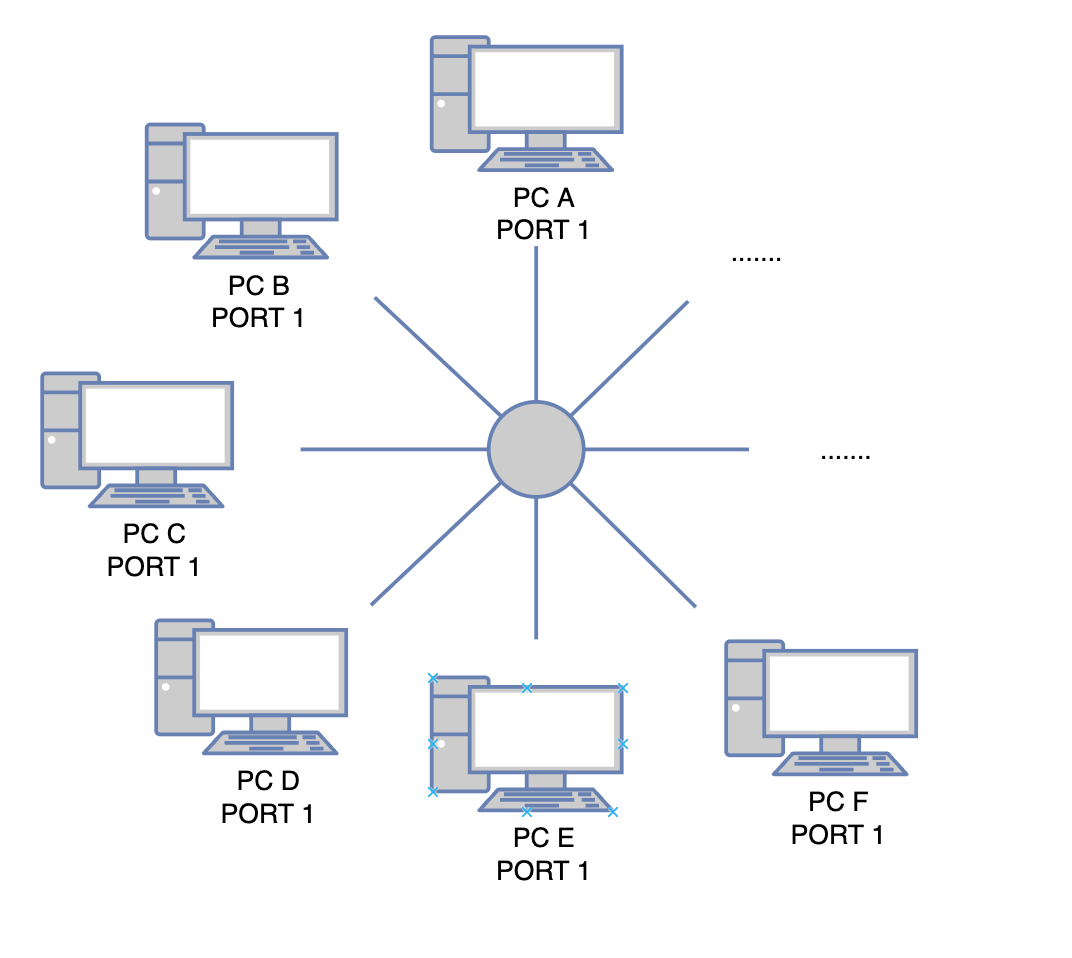
如图所示是一个环形总线,每一个环形总线的接线处挂载了一个网络终端,只需要占用网络终端的一个端口。
通信过程:
- PC A 想要发送一个消息给 PC D,就会通过连接线,发送一个消息,总线上挂载的所有机器都会收到这个消息。
- 为了区分不同的机器,我们给每个网络设备预先分配一个独一无二的ID号,我们叫做MAC地址。在发送的消息头部,我们标记消息的来源设备的MAC地址,以及目的设备的MAC地址。
- 所有挂载在总线上的设备都会接受到这个信号,在确认消息和自己无关后,会直接忽略,只有PC D会获取该消息,并进行后续操作。
这个环形总线,在现实中,我们对应的设备就是集线器。
因此,上述模型也可以画成:
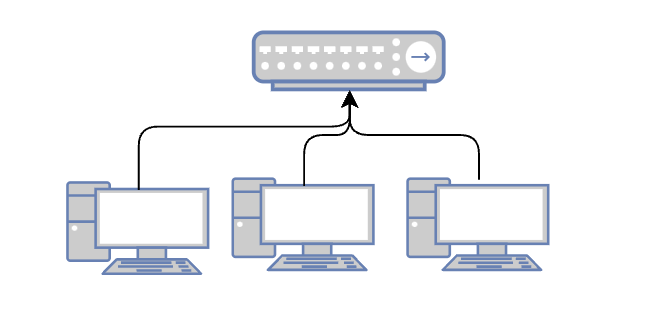
不过这种改进的问题就是,物理层的设备没有基本的逻辑处理机制,只进行无脑转发,每发一次消息,都会影响整个链路的机器,频繁的信息中断对正常的软件运行干扰很大。
我们对集线器稍加改造,加上MAC地址的缓存和学习能力,就得到了一个新的设备: 交换机。
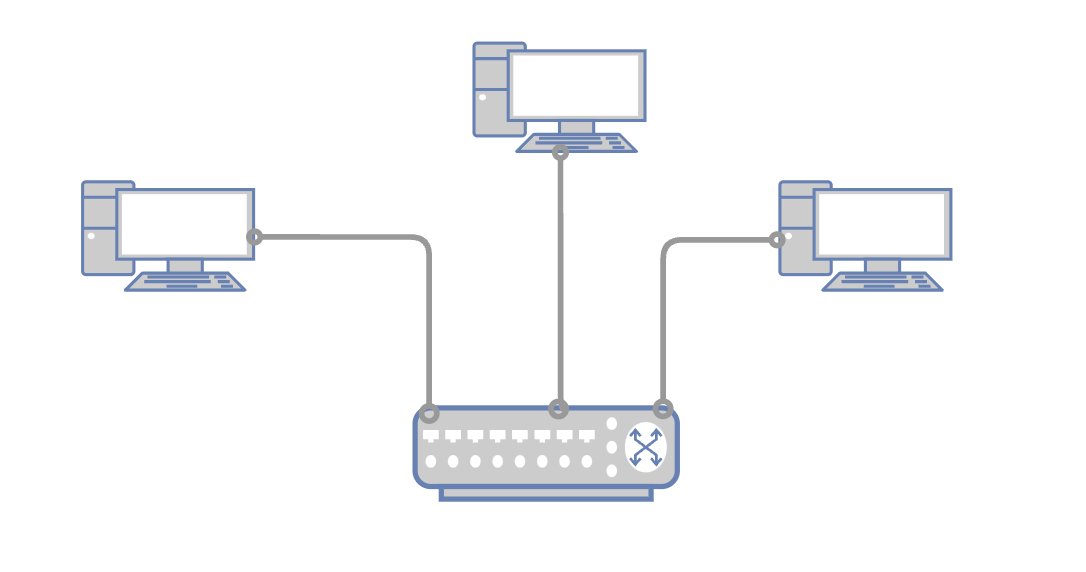
MAC地址的缓存能力是指:
- 交换机上面有很多端口,交换机内部会存储端口上挂载的终端设备MAC地址和端口号的映射关系,那么,如果之前消息的路径已经走通过,交换机就可以根据消息的目的MAC地址,直接转发消息到指定的端口连接中
MAC地址的学习能力是指:
- 在缓存中,没有目的MAC地址的情况下,交换机会提供一种机制主动获取MAC地址对应的端口并缓存结果,之后无需重复获取。实际原理和集线器的操作类型,对所有端口发送消息,成功响应的端口就是目的MAC设备挂载的端口。我们称这个行为叫广播。
经过上述过程的演进,我们可以得到一个小型的网络拓扑模型,交换机的端口数量决定了这个网络内互联的终端数量。
那这够用吗?
显然不够的。
如果要更大规模的网络,我们可以将交换机互相连接。
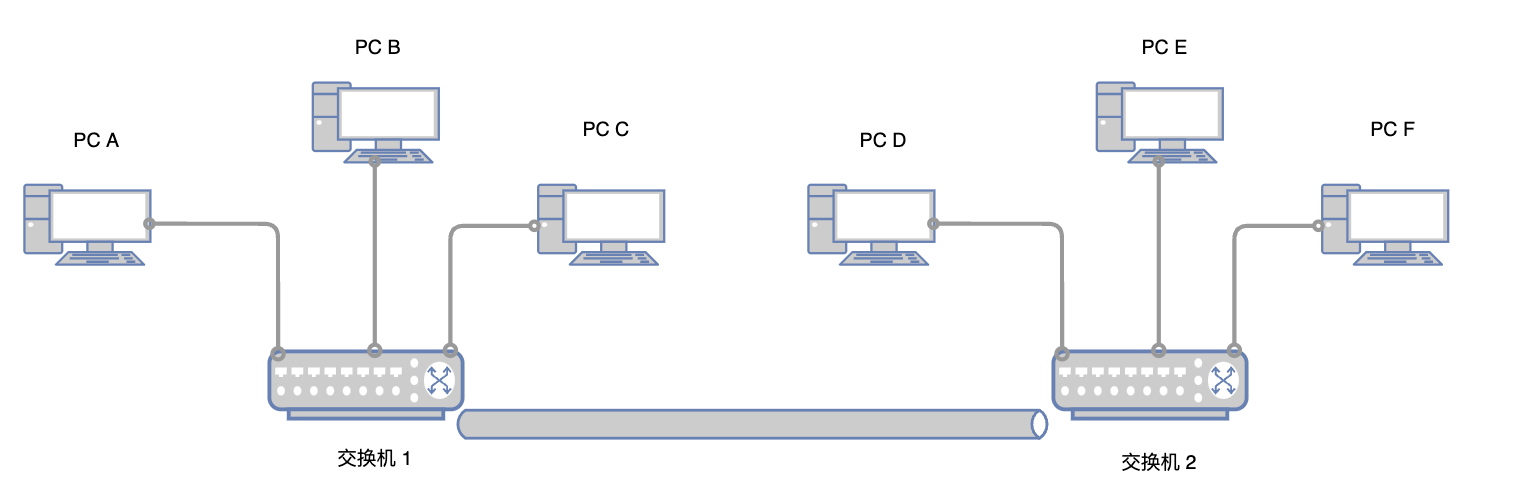
从集线器到交换机的演变过程中,还有一个设备:网桥。
网桥他也是工作在数据链路层的设备,他可以识别MAC地址,网桥和交换机的作用类似,也是将从一个端口输入的数据,转发到另一个端口,只不过他主要是用来连接两个同构网络。也就是一个网段内的网络。
到此为止,我们只涉及到了数据链路层的协议,也就是MAC地址、广播这些。这种机制,也许在拥有几百个上网终端的网络内是足够的,但是如果想要做到全球互联,能力上捉襟见肘。
1.1.3 规模进一步的膨胀–路由、子网联通
MAC地址可以看做是设备的身份证,通常不会轻易改变且具有唯一标志性。那么我们为什么还需要IP地址呢?
IP地址的作用一个是标记,在一个局域网内,设备的IP本身和MAC地址一样,是具有唯一性的,但是相比MAC地址,他更灵活,可以变更。更重要的作用是他具有路由寻址的作用。
IP地址约等于是一个人的住址。知道一个人的身份证,除非建立非常大的人口登记住址表,否则并不能很快的找到某个人。而如果你知道了这个人住在中国上海市浦东新区纳贤路200弄,那你就可以很快的定位到。
我们看一看IP协议的一些内容:
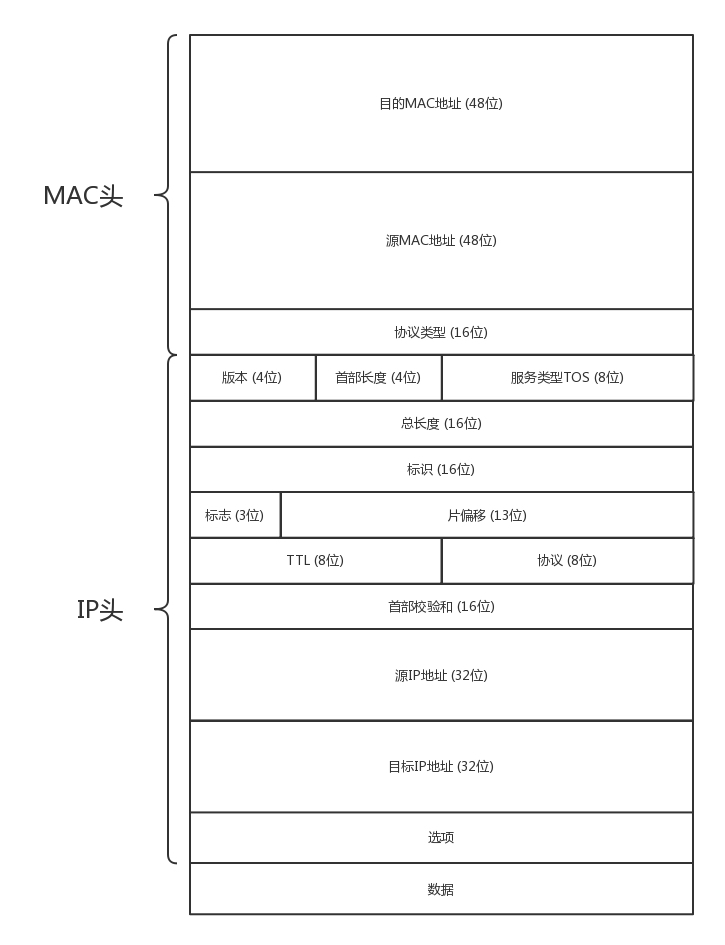
首先是IP头的详细组成部分,包含了版本、首部长度、TOS、数据包总长度、源IP地址和目标IP地址等等。
MAC地址是16位的字符,IP地址在设计时,也比较简单直接,是一个32位的二进制,为了方便辨认,8个位为一段,IP地址就会被表现为:
192.168.1.0/24这样的形式。
后面的24表示的是子网掩码。
这里就涉及一个概念,什么是子网?
IPV4的IP地址中,32个数字其实被分成了两部分,前面的一部分数字叫做网络号,后面的数字组成主机号,但是二者一共就32位,IP协议规定,同一个网络号的机器之间是可以”直接”互通的,不是一个网络号的机器,如果需要互通,必须通过网络层的设备作为媒介,比如路由器、网关。
这里同一个网络号,就是同一个子网。子网掩码标记了网络号使用数字的范围。
比如24,也就是前24位是网络号,那么我们的网络号范围,反映在二进制上,就是 11111111.11111111.11111111.00000000,拿到一个IP地址后,将它和子网掩码进行与操作,如果得出的结果和本机IP计算得到的结果一致,说明二者是在同一个子网,否则不是。
先看第一种情况,两个机器在同一个子网内,如何进行互联?
换个方式思考,我们目前已知的:
- 在一个子网内,如何使用MAC地址进行互联
- 我们知道本机和目标机器的IP地址、MAC地址
我们想要做的事情: - 子网内机器的互联
显而易见,如果有一种方式,能让我们通过IP地址获得目标机器的MAC地址,这条路就通顺了。
ARP协议应运而生,二层设备可以通过广播获取MAC地址和端口的映射关系,三层设备就可以如法炮制,通过广播获取IP地址和MAC地址的映射关系。
之后的操作就和之前一样,在同一个二层网络内进行。
两个机器在不同的子网内,如何进行互联?
我们通常预先规定子网内默认的网关地址、广播地址。
例如192.168.1.0/24l里,我们可以使用192.168.1.1作为默认网关地址,192.168.255.255作为广播地址。
在硬件层面,默认网关通向的是路由器,路由器作为一个三层设备,具有解析三层协议,取出IP头、MAC头的能力。(同理,X层设备其实就是说明这个设备可以处理X层的协议)
路由器也是一个具有多个端口的设备,但是与前面提到的二层设备不同,路由器每一个端口背后就是一个网卡,拥有自己独立的MAC地址。每个端口可以分别连接一个局域网,如果说一个局域网就是一个独立的海岛,那么路由器就像是一个用于沟通的桥,在每个岛都有自己的出入口。
假定设备A的IP是192.168.1.2,设备B的IP地址是192.168.0.3,两个子网通过一个路由器进行连接,路由器的端口1连在A所在的子网,IP地址是192.168.1.1,端口2连接在B所在的子网,IP地址是192.168.0.1
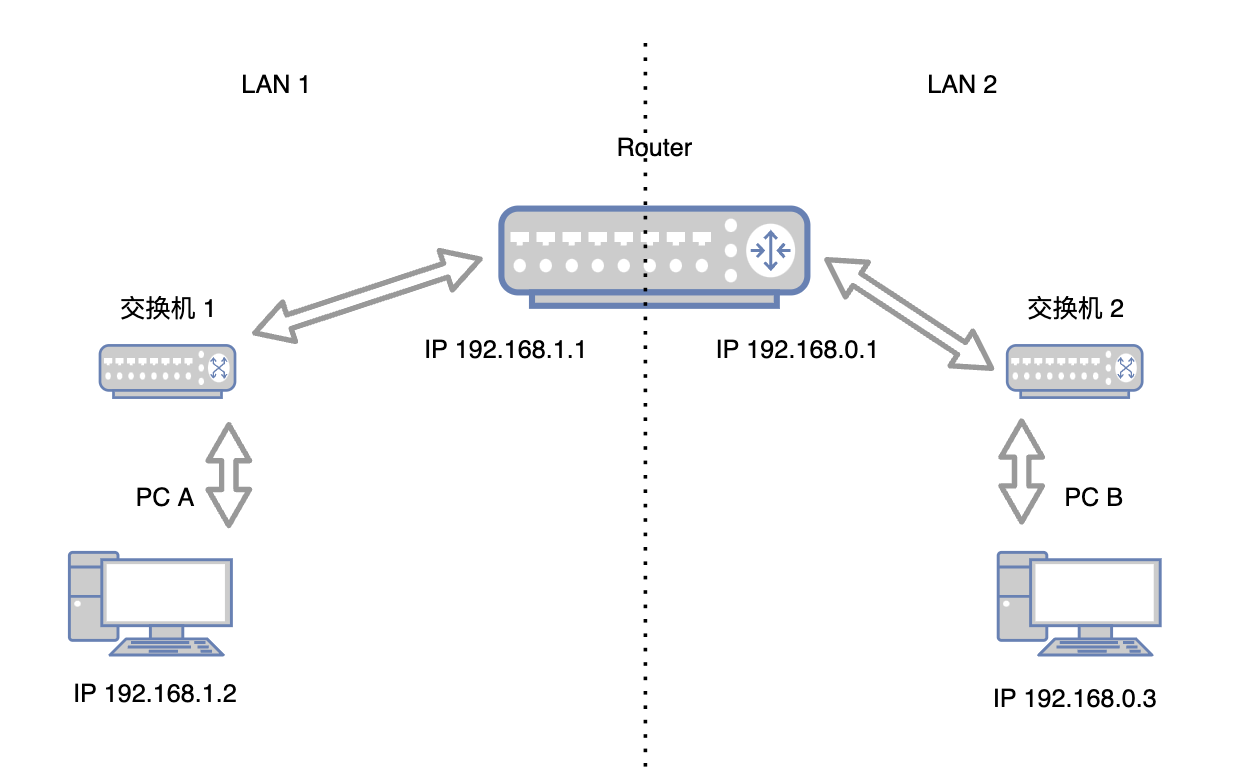
A想要发消息给B,会执行以下步骤:
- 将A的子网掩码分别和A\B的IP地址进行与运算,一个结果是
192.168.1.0,一个结果是192.168.0.0,显然分属两个子网,A和B无法直接进行网络互通。 - A发送消息给默认网关
192.168.0.1,也就是子网内的路由器的端口1 - 路由器内部会维护一个子网网段和端口的映射关系,我们叫做路由表,查询可知,目标IP在端口2连接的子网中
- 得到目标IP的位置信息后,整个数据传输过程可以分为两端,一段是从A到路由器的端口1,第二段是从路由器的断口2到B
对应的数据包内容就是:

不过网络层的数据传输就这么简单吗?
实际要复杂很多,例如如何获取路由表:我们可以把路由分类静态路由和动态路由两种,定死的规则叫做静态路由,比如我们可以在路由器中写死,某一个网段的数据直接转发到端口3,但是静态路由的能力有限,更多时间,我们需要使用动态路由。
动态路由的算法包括拓扑排序、路径选择、存活检测等内容,我也没有完全掌握,但是这不影响我们对整体流程的理解。
还有一个细节,上面的这个图中,由于二层网络的载体发生了变化,也就是第一段的发送者是A,而第二段的发送者是路由器的端口2,他们分属不同的子网,那么二层数据帧的MAC头就一定会发生变化。
但是IP头就一定不会变吗?
其实未必的,这取决于网关的类型。不改变IP地址的网关,我们称为转发网关;改变IP地址的网关,我们称为NAT网关。
上面画的图,其实是属于转发网关的功能。NAT(Network Address Translation,网络地址转换)网关在转发三层包的时候,会对原有的IP地址进行修改。
什么场景会进行使用呢?比如家庭的路由器,如果运营商分配了一个运营商的公网访问IP,在对外通信的时候,家庭局域网的IP地址对外面的公网来说其实是没有意义的,这个时候,在出网关的时候,就需要做一层网络地址转换,将局域网内的IP替换成运营商分配的公网IP。
以上是数据链路层层和IP层网络互联的一些流程,但是实际的过程是十分复杂的,这里只是做了简单叙述,方便我们后续对容器和云计算网络模型的理解。
1.2 VLAN与VXLAN
1.2.1 VLAN
前面提到,在网络连接的过程中,我们不可避免的需要使用到广播,也就是向网络内所有的机器发送一次数据。
当网络内机器很多时,可想而知,一定频率的广播事件肯定会降低系统的处理性能。
那么怎么可以降低广播对整个网络的影响呢?
我们可以使用隔离的方式,降低广播的范围,一个是物理隔离,也就是直接细分子网,使得一个交换机的广播只局限于自己局域网的几个机器。
或者是虚拟隔离,组网拓扑不变,但是我们可以给一个子网内的机器进行分组,比如我们一个部门内,有开发、PM、HRBP,不同的职能人员,很多情况下,开发只想和开发沟通,HR只想和HR上级沟通,但是不影响我们处于同一个办公场所。我们要做的只是对机器进行逻辑上的分组即可。
要怎么实现呢?
VLAN(Virtual Local Area Network, 虚拟局域网)就可以。
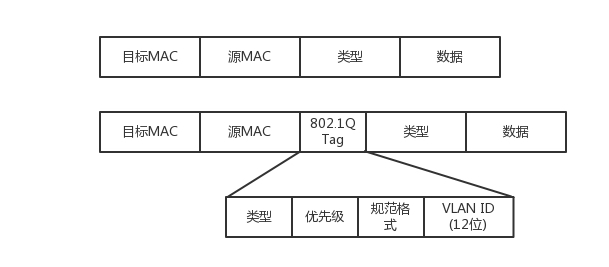
我们只需要在原来的二层的头上加一个TAG,里面有一个VLAN ID,一共12位。为什么是12位呢?因为12位可以划分4096个VLAN。这样够吗?现在的情况证明,目前云计算厂商里面绝对不止4096个用户。当然每个用户需要一个VLAN了,那怎么进行扩展呢,先埋个伏笔。
如果我们买的交换机是支持VLAN的,当这个交换机把二层的头取下来的时候,就能够识别这个VLAN ID。这样只有相同VLAN的包,才会互相转发,不同VLAN的包,是看不到的。这样广播问题和安全问题就都能够解决了。
1.2.2 VXLAN
上面提到,VLAN的局限性:最多只支持4096组用户。
这对于大型网络服务提供商来说,明显不够用的,这个时候我们要么改造现有协议,要么提出新的改进协议。
考虑到现实情况下,这个协议已经被广泛使用,这个时候提出新的协议可能更便于与旧系统兼容。
VXLAN(Virtual eXtensive Local Area Network)应运而生。
在了解它的工作模式之前,我们先了解一下什么是隧道协议
1.2.2.1 隧道协议
隧道协议(Tunneling Protocol)[1]是一种网络协议,在其中,使用一种网络协议(发送协议),将另一个不同的网络协议,封装在负载部分。使用隧道的原因是在不兼容的网络上传输数据,或在不安全网络上提供一个安全路径。
光看解释是很迷糊的,我们可以换一个思路。
我们之前说的网络分层模型:
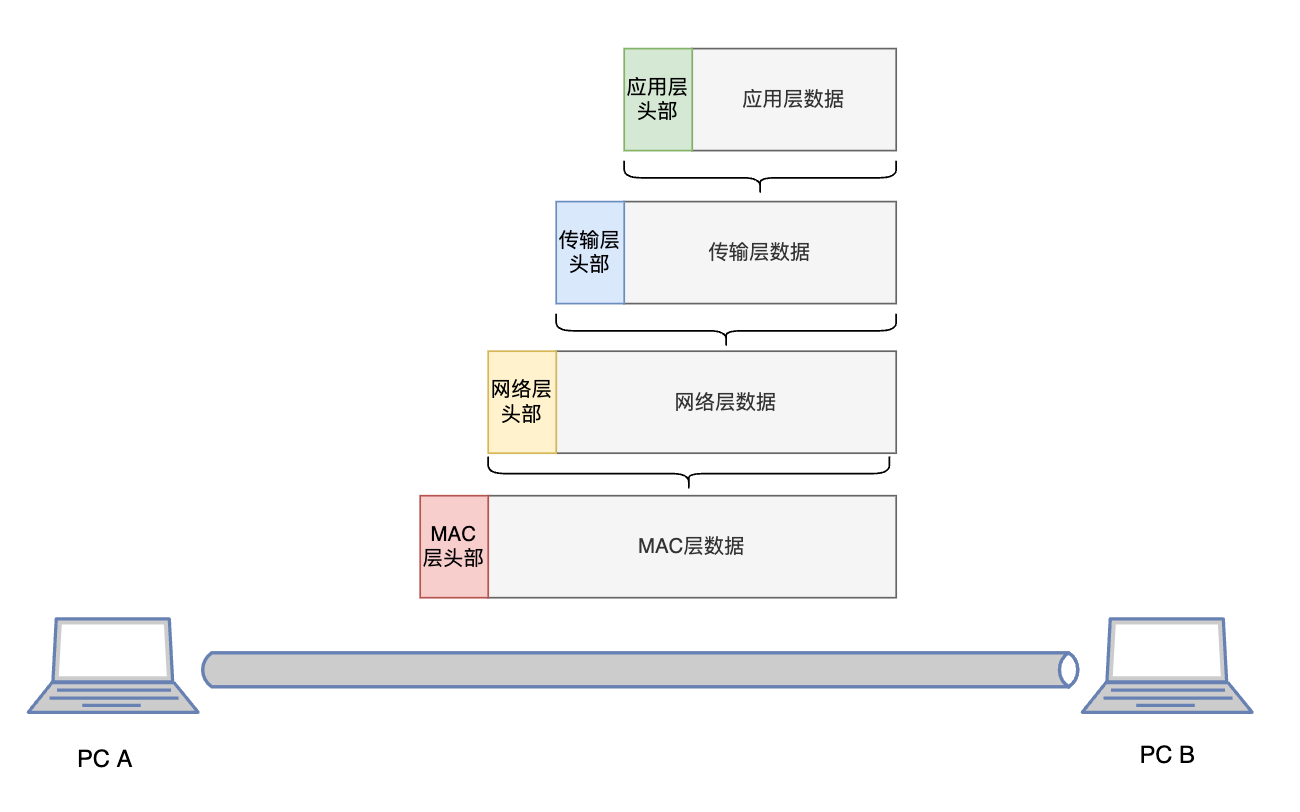
这里每一层的数据里,嵌套的都是上一层的信息,构成了一个完整的数据包。
那如果我在MAC层里嵌套另一个完成的MAC层数据呢?或者在IP层数据里嵌套一个完整的MAC层数据呢?
你可能会问:可是真实的MAC地址只有一个啊,嵌套多个同层或者低层数据,有什么意义呢?
没错真实的只有一个,但是我们可以构造虚拟的,很多场景下,我们往往就是需要虚拟的信息,才能实现过去做不到的事情。
例如SSH(Secure Shell,安全外壳协议)协议,你有没有想过,远程机器的端口是限制其他机器访问的,但是我们ssh上去后,就可以访问了呢?其实实现原理就是通过隧道协议,把发送到目的端口的请求,包装在ssh的请求中,然后进行端口请求的转发。同理还有VPN协议,可以自行了解。
VXLAN也利用了隧道协议。
1.2.2.2 VXLAN简述
在隧道技术中,底层的物理网络设备组成的网络我们称为Underlay网络,而用于虚拟机和云中的这些技术组成的网络称为Overlay网络,这是一种基于物理网络的虚拟化网络实现。
VXLAN是从二层外面就套了一个VXLAN的头,这里面包含的VXLAN ID为24位,可以表示最多1600万的用户。在VXLAN头外面还封装了UDP、IP,以及外层的MAC头。
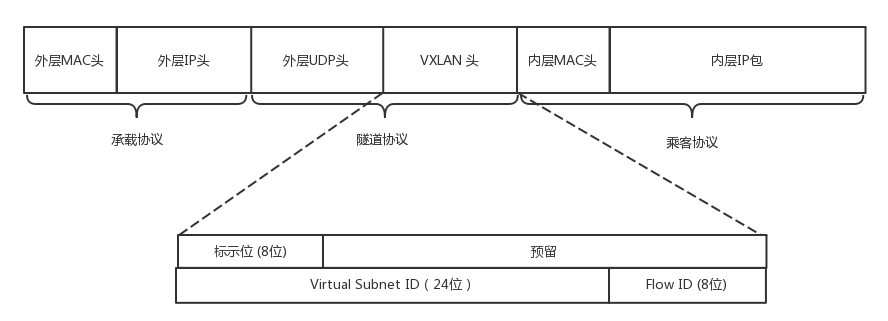
对于跑在物理网络的协议,通常我们需要一个设备对协议进行解、封装,而VXLAN是虚拟化的协议,并没有专门的设备进行处理,不过我们在软件上进行实现,把实现这个功能的点称为VTEP(VXLAN Tunnel Endpoint)。VETP会解封数据包中的数据,并进行处理或者转发。
VTEP可以根据VXLAN ID区分不同的网络,在云计算网络中,VTEP相当于虚拟机网络的管家。每台物理机上都可以有一个VTEP。每个虚拟机启动的时候,都需要向这个VTEP管家注册,每个VTEP都知道自己上面注册了多少个虚拟机。当虚拟机要跨VTEP进行通信的时候,需要通过VTEP代理进行,由VTEP进行包的封装和解封装。
借助这样的实现,我们发现,原本二层网络物理上的界限不存在了,只要两个机器之间 可以进行IP层的互联,两个机器就可以被划分到一个VNI相同的虚拟网络内。我们也把这个叫做大二层域。
基于VXLAN,虚机可以变化所在的”子网”,网络的连接和隔离,也有了很大的自由度。
以上就是VLAN和VXLAN的一些简述,他们将在K8s的网络中发挥怎样的作用呢,我们拭目以待。
2. 单机容器网络原理
2.1 容器网络构成
linux的容器依赖于cgroup和namespace技术,其中namespace用于隔离资源,cgroup技术用于控制资源规模。
我们暂且忽略它们的运作细节,可以把运行在主机上的容器们,想象成是一个个独立的机器,有自己的网络栈和网络设备。
这些虚拟的容器之间如果相互连接呢?
Linux提供了Veth Pair这个工具。
Veth Pair是专门用于跨namespace网络连接的虚拟设备,Veth Pair总是成对出现的,它的一端出现在一个namespace里,另一端可以在另一个namespace的网络栈里,可以把它理解成一个工作在二层网络的虚拟设备。创建并配置正确后,向其一端输入数据,VETH会改变数据的方向并将其送入内核网络子系统,完成数据的注入,而在另一端则能读到此数据。
可以想象成一根网线,这根网线专门用于跨namespace的网络连接,大概类似这样:
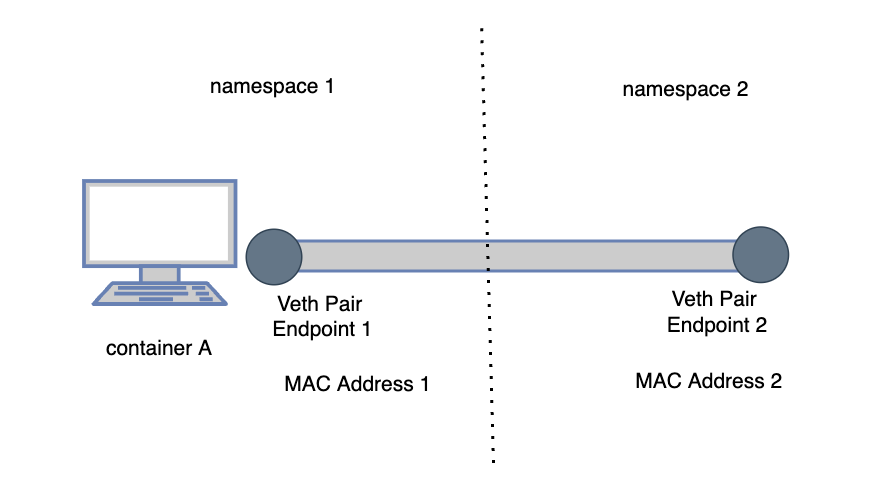
还有就是这个虚拟设备的两端都有自己的Mac地址,所以在他们自己的namespace里,Veth Pair的一端完全可以看做一个独立的二层网络设备。
我们在容器创建之后,可以给创建一个Veth Pair,一端在容器内,一端在主机的默认namespace下,那么就可以实现主机网络和容器的联通。
那如果要实现容器之间的相互通信,该怎么办呢?
联系一开始我们学习到的网络设备,其实我们这个需要的就是一个负责在二层网络设备之间传递数据包的虚拟设备,承担类似交换机的职责。
这个虚拟设备就是网桥,网桥可以看做是一种特殊的交换机,职责是差不多的。在docker的实现方案里,docker引擎会在宿主机上搭建一个docker0网桥,所有的容器创建后,会创建一个Veth Pair,一端在容器自己的命名空间,另一端和网桥相连。大概就是如图所示:
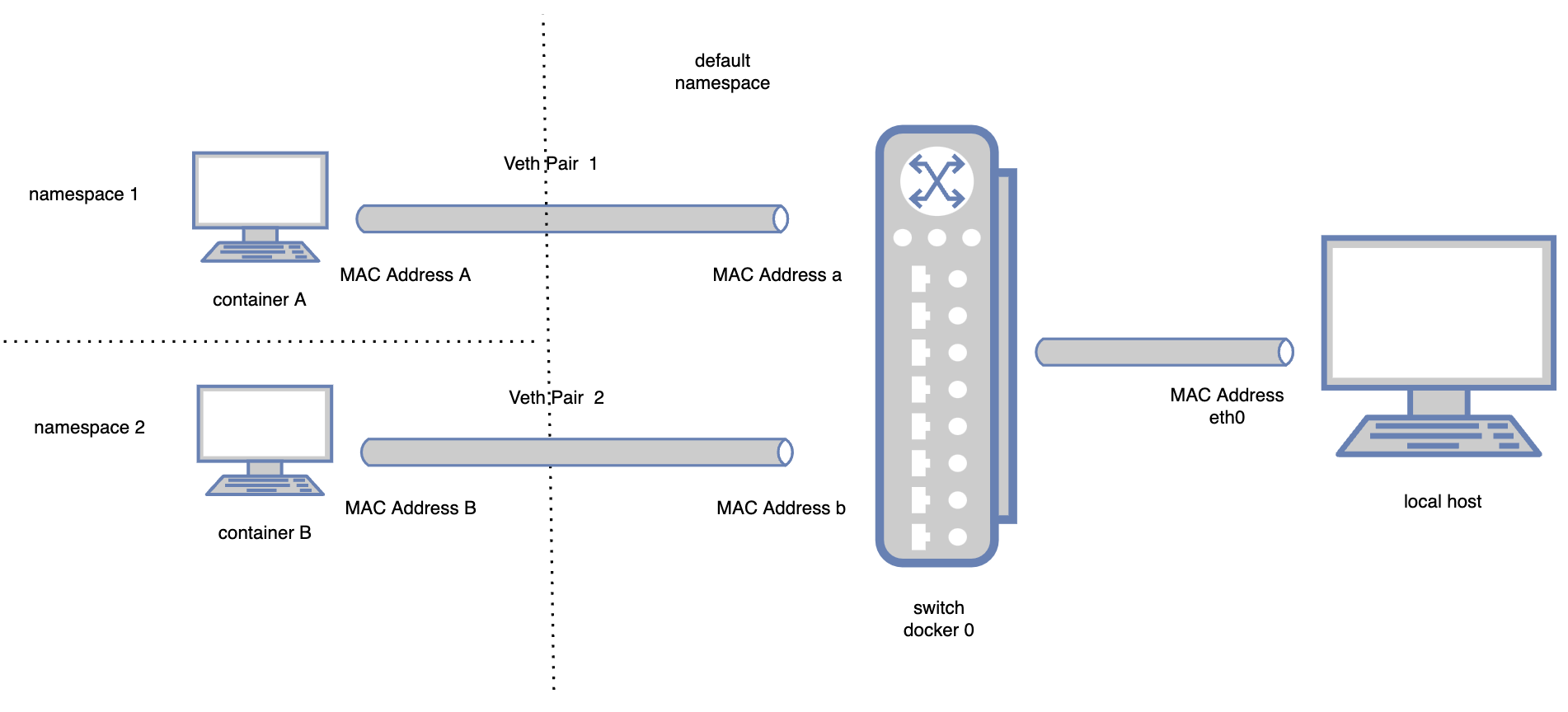
此外,容器引擎会为每个容器分配一个虚拟IP,docker0网桥在宿主机上有自己的MAC和IP地址,有点像是集路由器、交换机于一体的角色。
这样,宿主机上的网络拓扑结构就比较清晰了,可以类比成一组子网内的机器互相通信以及与子网外的宿主机进行通信的模型。
2.2 容器网络工作细节
接下来,我们继续看容器网络如何工作的。
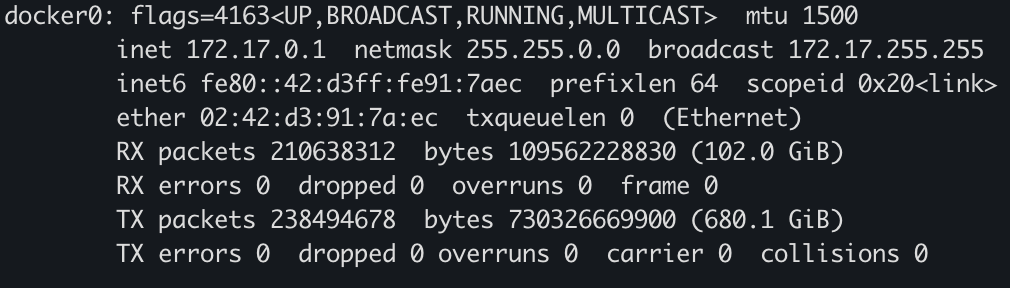
我们启动docker服务,在宿主机上执行ifconfig可以看到docker0网桥的基本信息:
我们启动两个容器,分别叫nettools-1和nettools-2,如下所示:

这个时候,我们分别进到这两个容器里,查看他们的网络设备信息
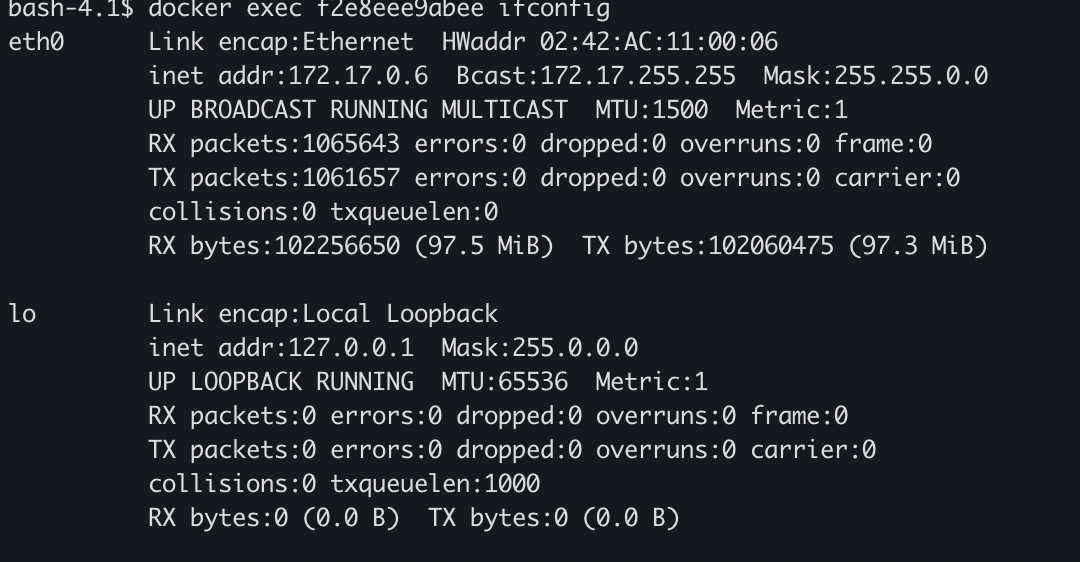
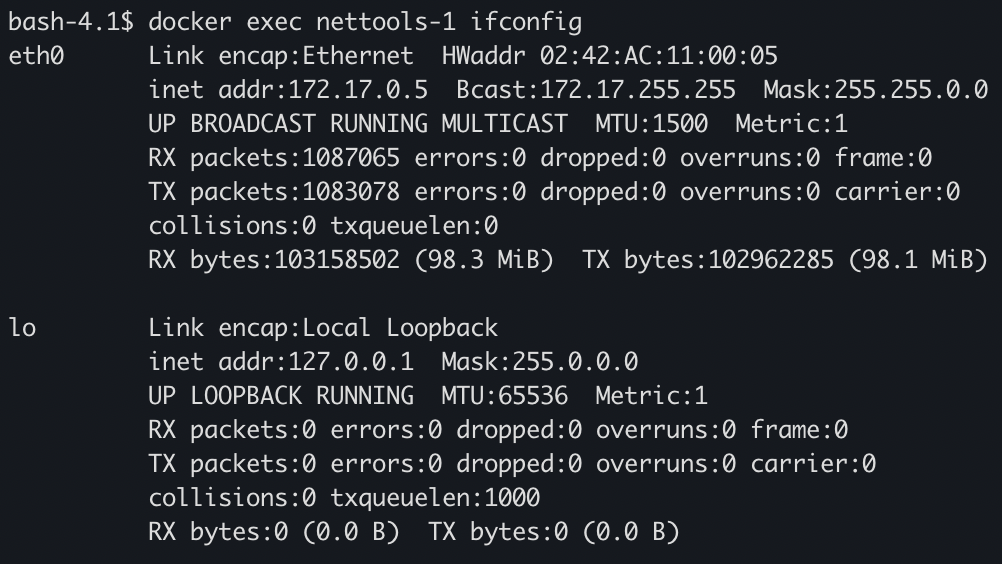
可以看到IP分别是172.17.0.5、172.17.0.6
返回宿主机,再查看网络设备,就会多出来两个veth网卡
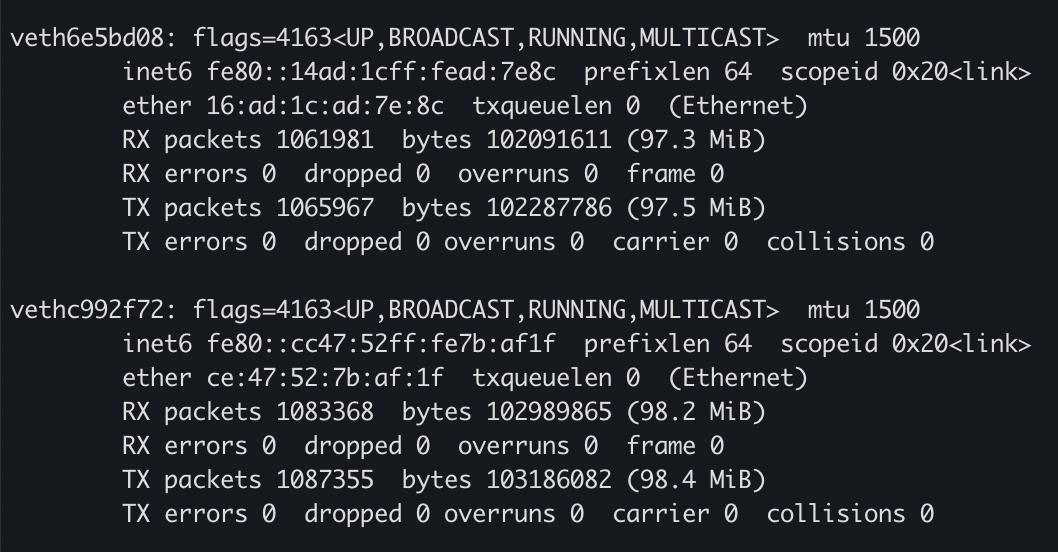
我们可以再看看容器内部的路由表,统统都是走默认网关到docker0网桥的:


我们可以发现,docker0网桥和容器是处于同一个网段的172.17.0.0/16
那么单个机器上,容器的互联方案就很容易想到了:
- 容器A访问容器B的时候,会发送一个三层网络的数据包,如果第一次通信,不知道B的MAC地址,则需要通过ARP协议进行获取
- 于是A通过网络栈发起ARP的请求,请求通过Veth Pair的一端进入到docker 0 网桥,docker 0 网桥如果不知道B的IP和MAC的映射,则会发出广播给网段
172.17.0.0/16内的虚拟机器,然后将结果返回给A - A继续发出三层网络数据包
- 这个网络的数据包进入到容器A的网络栈中,通过A自己的eth0发出
- 随后,经由Veth Pair的作用,A的三层网络数据包直接到达了主机网络栈的网卡Veth A
- Veth A 将数据交给了docker0网桥,docker0网桥再将数据包转发给容器B,这就完成了一次容器内部的访问
再进一步,容器和宿主机之间的访问呢?
我们可以看下宿主机的路由表设置

结果也就很明显了,
主机网络和容器网络之间的连接,可以看做是两个子网之间的连接,docker0网桥则在中间充当路由器的角色
主机网络发起的请求,如果命中docker0子网的路由规则,就会发送到主机上的容器中,容器发起的请求,如果ip不在容器网段内,则会经由docker0网桥最终发送给主机网络处理。
3. 总结
本篇文档描述了二、三层网络模型的运转规则,进而介绍了单机容器网络的运行模式。
我们可以发现,容器网络并不是一个凭空产生的网络模型,它的运作方式完全可以套用传统的网络模型去分析。
那么对于跨主机的容器网络,它的模型是怎样的呢?
是不是说,如果存在一种方式,把跨主机的容器,都放到一个子网上去,那么就可以类似单机容器网络那样去运转了呢?
细心的你可能注意到了,前面叙述的VLAN和VXLAN恰好可以发挥作用。
发表回复
要发表评论,您必须先登录。