Contents
跨主机容器网络的思路
在前一篇文章中,我们已经了解了单机容器网络的基本原理。
一个机器上的容器存在于一个子网中,通过一个虚拟网桥和外部实现通信互联。那么要想做到跨主机会有什么难点呢?
我们可以尝试做一些简单的分析,我们的目标是打造一个类似单机容器网络的子网环境,在这样的环境中,容器与容器之间可以实现网络的互联,这种互联是维持在什么层次的呢?
IP层的互通是最佳选择,一方面和单机容器网络的实现保持一脉相承,此外也是对现实网络的最佳模拟,我们可以把一些现实网络的寻址、路由策略无缝迁移,一个容器单元就类似一个主机,拥有独立的IP地址。
所以总结而言,跨主机的容器网络,需要做的就是利用一套网络转发规则或者技术手段,在多个主机之上构建一个虚拟的大二层网络,实现容器间的虚拟IP互联。
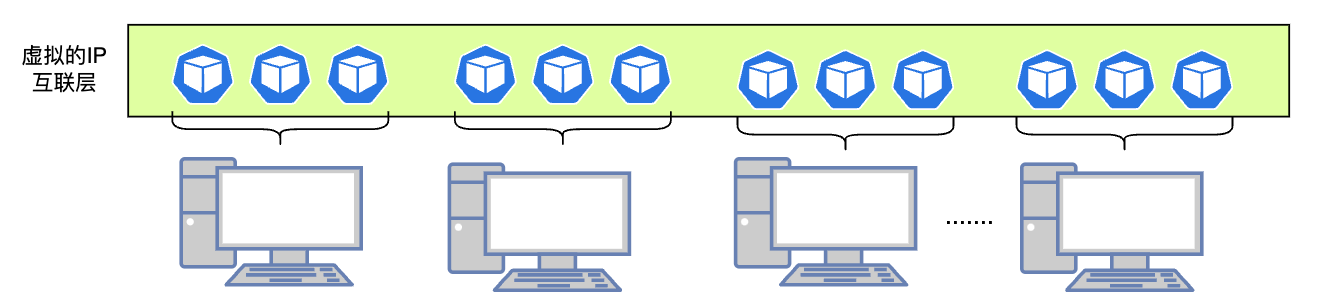
我们在前一篇中,提到过网络的隧道技术,通过在二层或者三层网络包中内嵌完整的IP数据包,就可以构建我们需要的虚拟子网了。这个思路是跨主机网络的关键。
在某些场景下,我们也可以借助一些特殊规则,实现纯三层网络的方案。
一些社区的实现方案
隧道网络方案
提到K8s的网络模型,离不开Flannel项目。由CoreOS开发的项目Flannel,可能是最直接和最受欢迎的CNI插件。它也是K8s早期默认的网络标准。开发该插件的CoreOS公司,和谷歌一道,制定了CNI(Container NetworkInterface)容器网络接口标准。
它是容器编排系统中最成熟的网络结构示例之一,许多常见的Kubernetes集群部署工具和许多Kubernetes发行版都可以默认安装Flannel。
Flannel定义了一套框架,在这套框架背后,有三种不同的后端实现。
分别为:
- UDP
- VXLAN
- host-gw
Flannel UDP
UDP模式是最简单,也性能最低的模式,目前基本被弃用了,不过我们可以从他入手,理解Flannel的框架。
我们假定集群内,有两个宿主机:
- Node1上存在容器container A,容器的虚拟IP是10.168.1.2, 对应的docker0网桥是10.168.1.1/24
- Node2上存在容器container B,容器的虚拟IP是10.168.2.3,对应的docker0网桥地址是10.168.2.1/24
我们希望借助Flannel的UDP模式,让容器A访问到容器B。
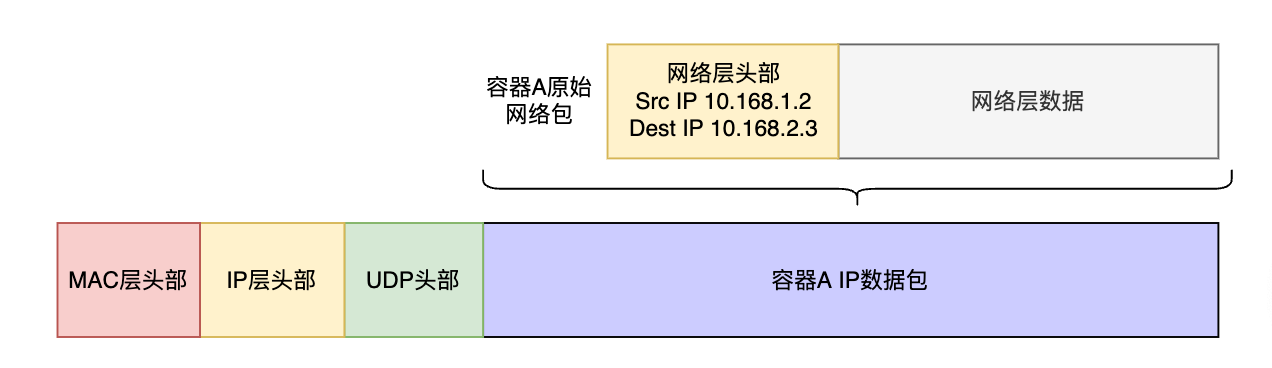
容器A的进程发出二层的网络包,结构如下:

根据单机的容器网络规则,网络包出容器后,触发容器的路由规则,交由Node1上的docker0网桥进行处理。
Node1上的Docker0网桥,看到目标IP后,发现该目标地址也不是自己管辖的子网网段范围,于是再交由宿主机的网络协议栈进行处理。
这个时候,网络包的走向就会取决于宿主机自身的路由规则。
显然,Flannel需要接管目的地址属于容器IP网段的网络包,方式就是在宿主机上新建路有规则。以Node1为例,会存在类似以下的路有规则;
default via 12.168.0.1 dev eth0
10.168.0.0/16 flannel0 proto kernel scope link src 10.168.1.0
10.168.1.1/24 dev docker0 proto kernel scope link src 10.168.1.1
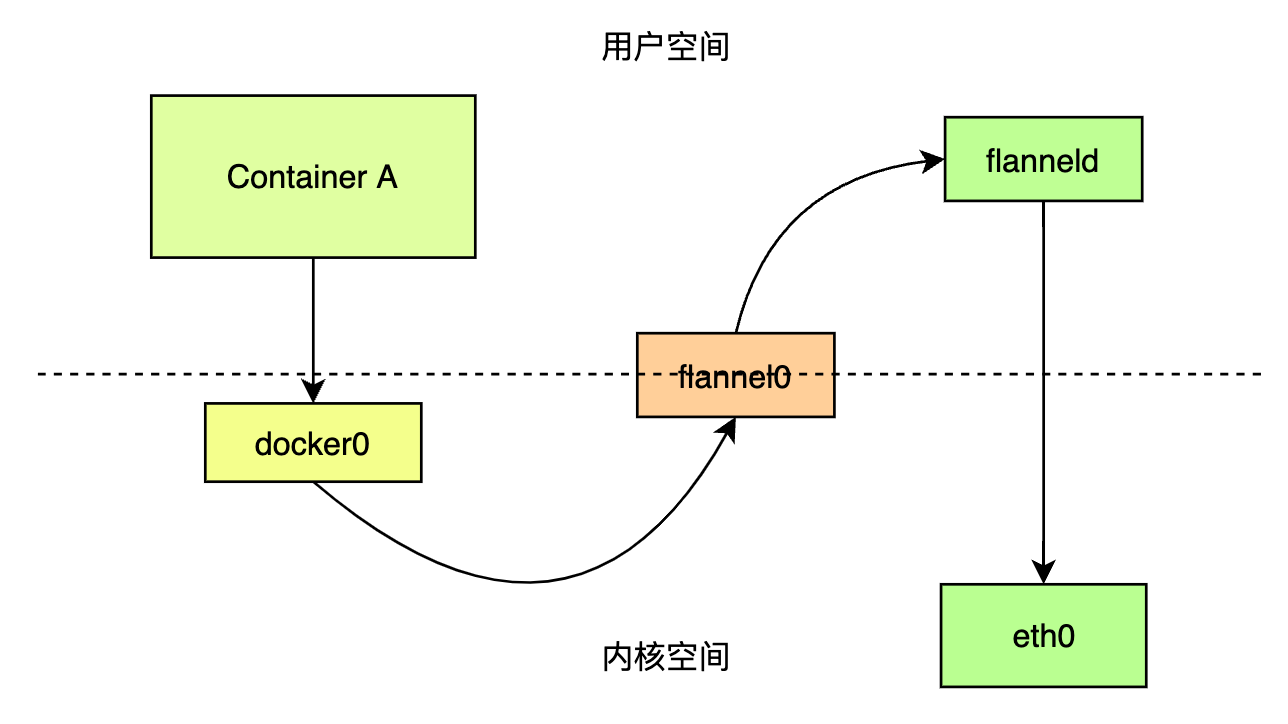
....有了上一篇的基础,显而易见,这个网络包会触发第二条规则,交给flannel0设备进行处理,这个flanel0属于linux中的一种TUN设备(tunnel设备),也就是隧道网络的设备。结合之前的叙述,这种设备的作用就是封装、解封装。
TNU设备是一种工作在三层上的网络设备,在操作系统内核和用户应用程序之间传递二层IP包。
例如在这里,flannel0设备接受到容器A的数据包时,该数据包存在于内核态(这里需要对linux的运行模式有一些基本了解,为了安全性,避免用户程序的崩溃影响了低层系统组件的稳定性,或者为了系统底层的权限隔离,linux会划分指定内存范围给内核软件使用,用户态程序则只能使用剩下的内存空间,这样带来的问题是有时候我们处理的是同一份数据,但是由于处理对象的转换,会导致在内核态和用户态之间频繁复制它,增加性能损耗,这是应用程序开发过程中尽量需要避免的场景),之后flannel0设备会将其交给后台的用户程序flanneld(Flannel在宿主机上运行的后台程序)进程,将网络包拷贝到用户态中。
Flannel会在etcd中维护容器子网和宿主机IP地址的对应关系。
所以,继续我们的数据包之旅。Node1上的flanneld拿到容器A的IP数据包后,看到它的目的地址属于Node2上的容器子网网段,就会将该IP包封装到一个UDP网络包,再次交给Node1的上的网络栈,发到Node2。这里会涉及到一次用户态到内核态的流转。
梳理下整个过程,我们可以画出这样的一个图:
出Node的数据包,结构如下所示:
构建虚拟二层网络的前提是宿主机之间是IP互联的。Node1的数据包到达Node2后,和正向过程类似,也会经过宿主机网络栈-flanneld进程-flannel0设备-docker0设备-container的路径传递到容器中。
不难发现,Flannel的UDP模式,其实就是用UDP协议,自己搭建了一个隧道网络,简单是简单,但是缺点也很明显,那就是频繁的在内核态和用户态之间切换,发送过程会经历三次转换,接受过程,也会有三次,一个数据包,会经过6次转换。
由于引入了更多的协议头,隧道网络本身就会降低传输效率,通过UDP协议,又加大了性能开销,那么我们之前了解过VXLAN协议,这个是IP in IP的隧道协议,linux原生就支持,为什么我们不用呢?
好问题,所以Flannel早就弃用了UDP模式,而是使用VXLAN。
Flannel VXLAN
回顾下VXLAN技术,VXLAN(Virtual extensible LAN 虚拟可扩展局域网)是linux内核本身就支持的一种网络虚拟化技术,所以使用VXLAN,隧道网络的解封装过程可以直接在内核态完成,降低性能损耗。
VXLAN协议中,需要一个特殊的网络设备VTEP作为『隧道』的两端,来辅助数据解析,VTEP(VXLAN tunnel end point,虚拟隧道端点),作用和其实和UDP模式里的flanneld进程功能类似,区别就是它工作在内核态,且只进行IP包的解封装。
VTEP是一个二层网络设备,具有自己的IP地址、MAC地址。
Flannel VXLAN的工作过程,如下图所示:
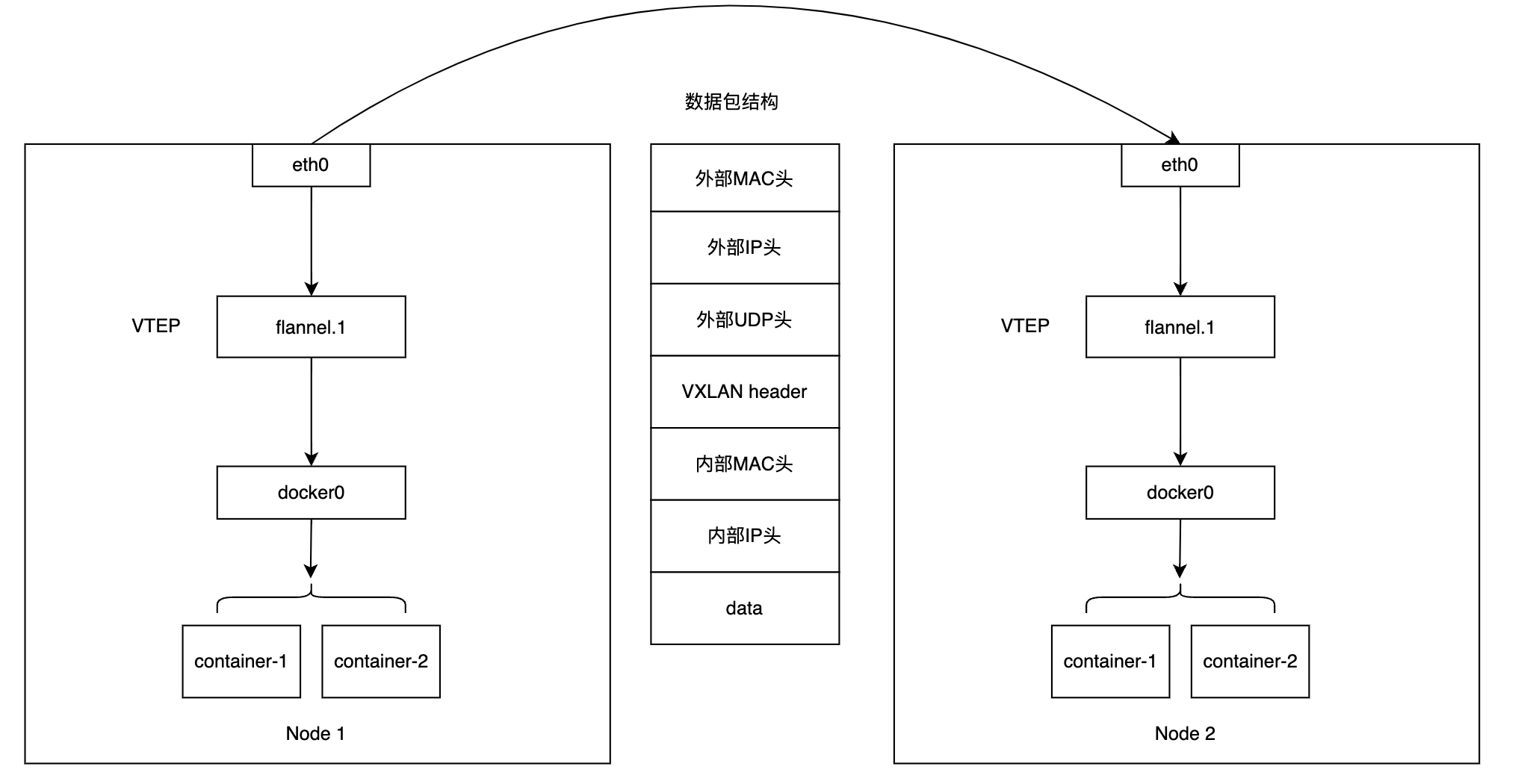
为了保障整个链路的畅通,Flannel还做了两件事:
- 修改宿主机的路有规则,将目的IP为容器地址的流量托管给VTEP设备
- VTEP设备之间的寻址需要设备的MAC地址,这部分需要借助ARP协议,flannel进程会负责写入不同node上VTEP设备MAC地址和IP地址的映射关系。
插播:k8s的通用网络模型
在k8s项目的演进过程中,为了项目能在众多容器编排平台迅速攻占市场,谷歌尽可能的做到了"简政放权",一方面是把自己的精力尽可能的放在容器编排的核心功能上,也就是资源调度,另一方面,也是充分利用开源社区的影响,吸引更多的团体能参与到项目中来。
所以k8s的许多功能都尽可能的做到了插件化,网络功能也不例外。
前面也提到,谷歌和CoreOS公司共同发布了CNI标准。
看完之前的内容不难发现,docker容器都连接在docker0网桥上,并且网络插件都会在宿主机上创建一个特殊的网络虚拟化设备,例如VTEP设备。但是容器的实现,并不知有docker一种,为了容器实现与容器编排平台的解耦,CNI标准中,维护了一个新的设备来替代docker0,这个设备叫CNI网桥,也就是cni0设备。
我们可以把cni0看做是docker0的替代,除此以外,k8s里还包含一些cni操作宿主机网络协议栈的实现,用于cni插件对于容器网络的基本操作,这个展开的话,会很繁琐,所以暂且搁置,我们只需要知道,在k8s的网络模型中,cni0网桥替代了docker0网桥即可,并且背后实现了一整套逻辑用于提到docker的网络方案。
纯三层网络方案
Flannel Host-gw
前面介绍了基于隧道网络协议的跨主机网络方案,除了这种模式,还有一种纯三层的网络方案。
Flannel Host-gw模式就是利用的这种方案。
不知道在学习前面的方案时,大家有没有产生过这样的好奇:
既然可以通过设置路由表,把容器的流量托管给网桥、网络虚拟设备,为什么不能通过路由表,将容器流量直接指向目的宿主机呢?
这样我们甚至不需要增加网络协议头部,几乎使用原生的网络传输速率。
要实现这种思路的方案,有一个前提,那就是宿主机之间是二层可达的。但是,很多情况下,我们的宿主机都不处于一个VLAN中,只能保证三层可达。
所以,我们可以推导出这种方案的优缺点:
优点:转发设备少,与隧道协议相比,不需要额外的网络协议头,效率高。
缺点:适用于规模小、所有宿主机处于同一个子网、宿主机之间二层可达的集群中,对于规模比较大的集群,Flannel的VXLAN模式更合适。
host-gw模式,他的运行模式如下:
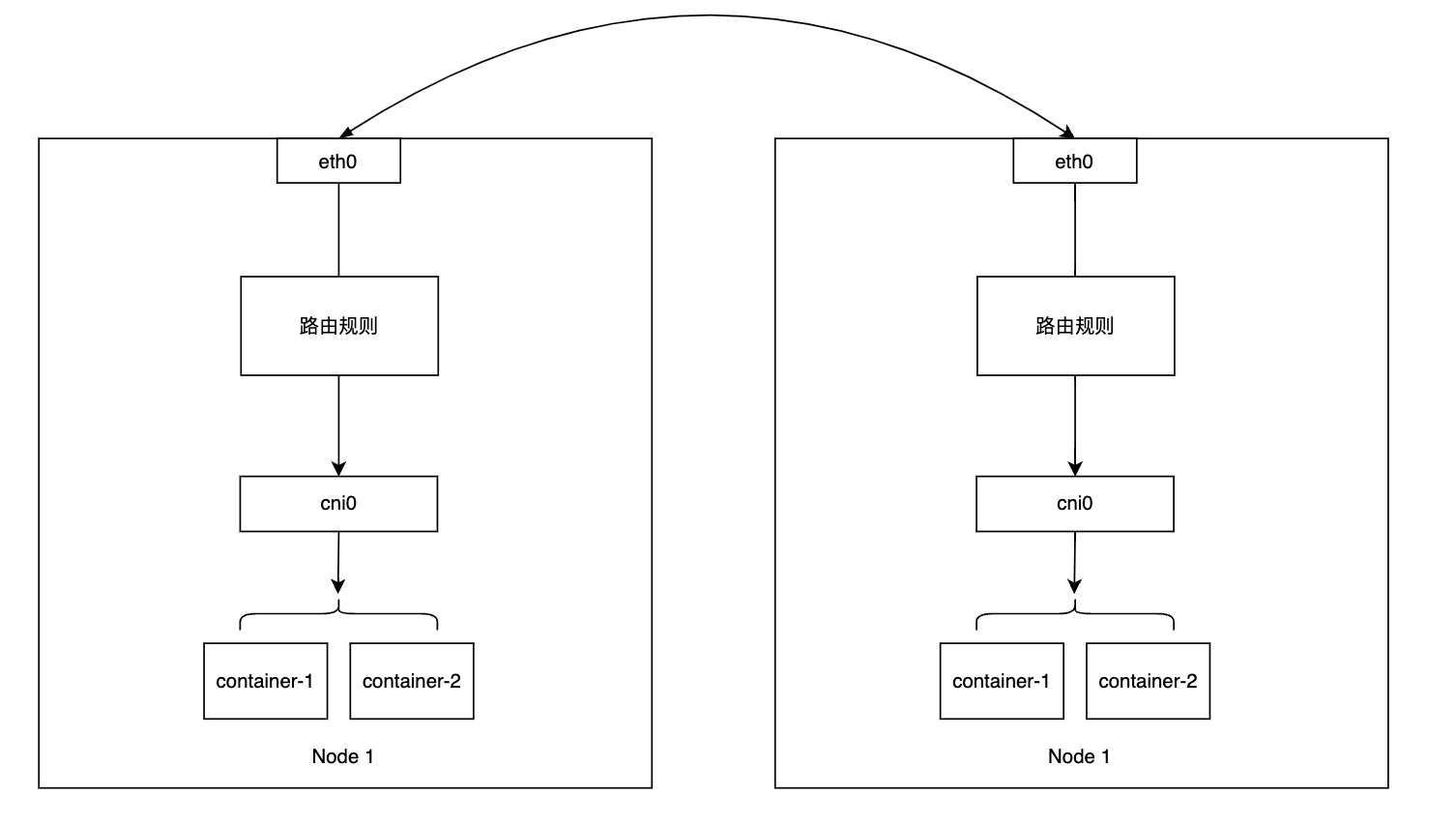
路由规则的格式:
<目的容器IP地址段> via <网关的IP地址(宿主机ip)> dev eht0Calico
除了Flannel,Calico也是纯三层网络方案的代表项目。
看了前一篇文章和上述Flannel的描述后,不知道你有没有这样的感觉,Flannel的开发者似乎一开始对现有网络协议并不是非常的熟悉,以至于在有现成的VXLAN的前提下,自己基于UDP又实现了一套类似的东西,这是k8s项目早期的历史包袱,所以导致,Flannel项目在host-gw模式上的实现,也不是那么干脆成熟。
与之不同,Calico更多的借鉴了现有计算机网络技术的成熟方案。
思路两者大致相同,但是不同于Flannel通过etcd和flanneld进程来维护路由信息不同,Calico项目使用了BGP(Border gateway protocol, 边界网关协议)。
BGP是一个Linux内核原生支持的专门用于不同集群之间路由信息、分布式无中心的路由协议。
Calico中,会把每一个宿主机看作是一个边界网关,互相之间可以分析记录容器网段的路由关系,互相交换路由规则,共同组成一个全联通的网络,与Flannel不同,BGP协议相对稳定,且更加强大。
Calico没有使用任何网桥设备,它主要由以下几个部分组成:
- Calico的CNI插件,负责和k8s对接
- Felix,k8s上的一个daemonset,负责在宿主机上修改路由规则,以及维护网络设备
- BIRD, BGP协议的客户端,负责分发路由规则
与Flannel Host-gw不同,Calico对大规模的集群,有另外一套组网方案。
由于每个宿主机都会看做一个边界路由,路由规则和宿主机的数量是平方关系,如果宿主机数量超过100个,那么推荐使用Calico的Router Reflector模式,在该模式下,Calico会指定几个专门的接待你负责跟所有节点建立BGP连接,学习全局的路由规则,其他节点只需要跟这几个节点通信即可。
这些Router Reflector节点实际承担起了代理的职责。
此外,集群规模增大后,会出现跨子网的情况,也就是只有二层联通,三层不可达,Calico也支持隧道协议的IPIP模式进行组网。
不难发现,Calico的组网方式非常灵活,适合多种场景,但是由于纯三层网络的协议会增加很多路由规则,给系统排故带来困难。
因此如果是在公有云上,宿主机网络本身比较简单,一般推荐使用更简单的host-gw模式,在私有部署环境中,Calico能覆盖更多长江,并具有更可靠的组网方式。
这里只是简单介绍,具有可以参考Calico的官网:
https://projectcalico.docs.tigera.io/reference/installation/api
总结
这篇文章主要介绍了K8s中跨主机容器网络的方案,相比上一篇,更加枯燥一些,也更贴近我们实际使用时涉及的组网方案。有兴趣的话,可以看看你自己的集群,使用的是什么插件,怎么组网的。
现在这个时间点,CNI插件多如牛毛,代表的有几个:
相对来说,Flannel是覆盖网络,主要是二层,Calico是纯三层的方案,除此以外,现在还有基于ebpf的cilium,可以支持三层、四层、七层的网络策略,性能据说相比iptables有很大提升,但是这个我暂时还不太了解。
发表回复
要发表评论,您必须先登录。